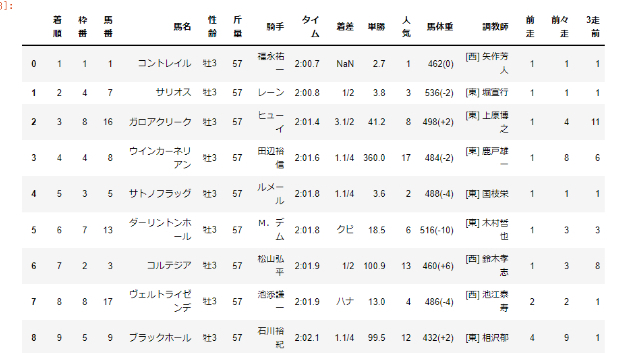
2021年8月7日 新潟11R 新潟日報賞(3勝クラス)
有料記事に向けたテスト投稿です。■複勝率100%final_corner_course_len_9R 5.8 [1, 0, 1, 0]
final_to_rank_9R -1.3333333333333333 [1, 1, 0, 0]
final_to_rank_course_len_9R 3.6 [1, 0, 1, 0]
first_corner_5R 3.6 [1, 2, 0, 0]
first_corner_allR 4.5625 [1, 1, 0, 0]
first_corner_course_len_5R 7.75 [2, 0, 0, 0]
first_corner_jockey_id_9R 4.5 [1, 1, 0, 0]
first_corner_jockey_id_allR 4.5 [1, 1, 0, 0]
first_corner_race_type_5R 3.6 [0, 2, 0, 0]
first_corner_race_type_allR 4.5625 [1, 1, 0, 0]
first_to_final_9R 0.5555555555555556 [0, 1, 1, 0]
first_to_final_race_type_9R 0.5555555555555556 [0, 1, 1, 0]
first_to_final_race_type_allR 0.125 [1, 0, 1, 0]
first_to_rank_5R 4.0 [1, 0, 1, 0]
first_to_rank_course_len_5R 1.0 [0, 1, 1, 0]
firs
0





.png)






.png)


.png)







.png)
.png)