タイトルにあるように、旅行会社の保有する顧客データ(属性や志向、営業担当との接触履歴等)を元に、旅行パッケージの成約率を予測するというものがあったので、参加してみました。こちらの課題は以前コンペにて掲げられたもの。
早速学習データの中身を確認。とりあえず、年齢や性別、結婚状況や月収、住んでる地域等の顧客データを確認。
まず大前提として機械学習モデルには男性、女性のような文字列はデータとして入力できないので、ラベルエンコーダーやOneHotEncoderのようなインスタンスで0、1のように”数値”に変換しないといけないです。
例えば”年齢”において、50歳や四十二などの文字列もそのままだとモデルが学習(特徴を掴むことやパターンを学習させること)ができないので、正規表現を用いて、すべて数値化します。
とりあえず、学習データの特徴量である、年齢や性別、月収など明らかに成約率に影響しそうなものを正規表現で全て数値化しました。
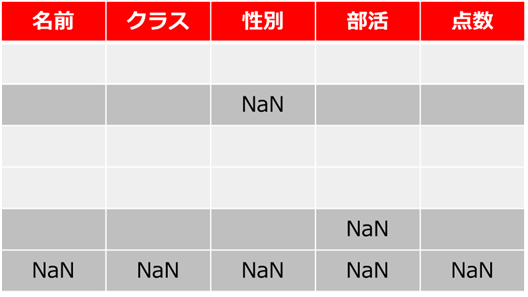
お次は欠損値の処理です。
欠損値とは、人為的なミスでデータが空白だったり、何らかの理由でデータが抜け落ちていたりするので、この欠損値を正しく穴埋め(処理)してやらないといけない。
(ただ、扱うモデルによっては欠損値に強いモデルもあります。)
今回のデータでは欠損値の数がデータ全体に対して少なめだったので、そのまま、平均値で補完しました。
※欠損値があまりに多い場合、その特徴量を削除したり、欠損値を埋めるための線形回帰モデルなど学習モデルの予測値で穴埋めすることもあります。
欠損値処理に関しては学習データだけでなく、テストデータにも適用させます。ここで大事なのはテストデータの欠損値をテストデータの平均で補完しないこと。
例えば、学習モデルがあったとしてこの学習モデルにテストデータを適用させて、モデルの精度を評価するシーンがあったとします。このとき、確かに与えるテストデータに欠損値があって、それらをテストデータの平均で補完すると、当然スコアって上がりますよね?平均なので、当然テストデータの特徴を捉えている値で補完しているわけですから。
でもこれって、モデルに都合がいいようにチューニングしてますよね。
一番の理想的な機械学習モデルってどんなデータが与えられてもちゃんと精度高く予想してくれることが重要なわけで、今回のチューニングでは確かに今回のデータで精度が高くなるかもですが、また全然特徴が異なる別のデータを与えると、精度は当然悪くなります。これでは意味がないのです。
次に外れ値の確認なのですが、今回は分類モデルで学習させるので、外れ値処理は行いませんでした。
(外れ値・・・明らかに他の値より大きかったり、小さすぎたりする値。人為的な入力ミスの場合や何らかの理由で桁数が他と異なるケース。また30000と30(万)のような表記ゆれによるもの)
なぜ、今回外れ値処理をしなかったというと、分類モデルにおいては0か1に振るいをかけるにあたり、閾値というものが内部で設定されています。そしてその閾値より大きいか小さいかで振るいにかけているので、桁数が多かろうが、少なかろうがその閾値で振るいにかけられているので、問題がないということです。
(今回のような0か1の二値分類の場合は外れ値は考慮しないが、0か1か2ような多値分類では無視できません)
ここで、優秀で万能なLightGBMモデルを利用します。私の場合、まずはこれから始めてます。その後にXGBoostやカテゴリカルな値に強いcatboostなどなど。
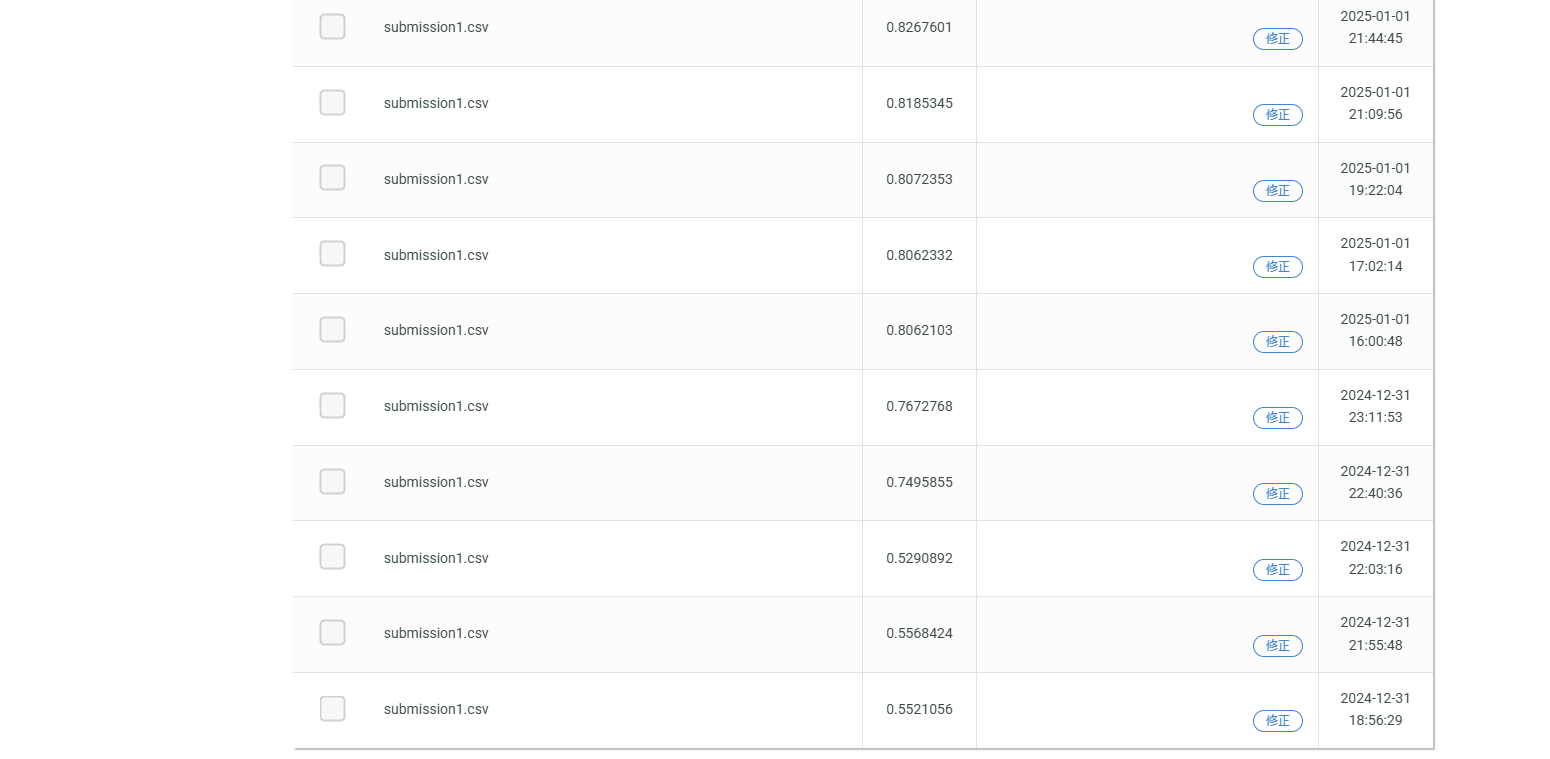
最終的なスコアは0.8377くらいまでいきました。約1500件中、350位くらいです。このスコアはLightGBMとcatboostのモデルのアンサンブル学習で得られたものです。
(アンサンブル学習 複数の機械学習モデルを組み合わせることで、お互いの不得手なパターンをお互いに支えながら、最終的な予測を行うこと)
当然、二つのモデルには得意不得意があるので、それはそれぞれの学習スコアの値を基に、”重み付け”で対処しました。
この後もモデルのパラメータをチューニングしたり、Optunaを利用したり、新たな特徴量を作成したりと試みましたが、いいスコアがでませんでした。
あと少しでメダルがもらえるとこまでいったのですが、ちょっと残念です。