1997年、ジェームズキャメロン監督による映画「TITANIC」は個人的に大好きな作品。当時はまだVHSが現役の時代。3時間を超えるボリュームでビデオ2本(前半パート・後半パート)で販売されていました。今思うとかなり分厚いケースでした笑。当時はフィルムが擦り切れる位、何度も何度も観たな~。
ストーリーもさることながら、当時では圧倒的なグラフィック映像で、またキャストも豪華俳優さんばかりで、また日本ではレオ様!とレオナルド・ディカプリオ旋風が巻き起こりましたね~。いやぁー、当時のディカプリオはマジで美少年そのものでした。こんな人、本当に実在するんだなって思うくらい。。
今回はそんな映画の題材となったタイタニック号沈没事故を例に機械学習における決定木分類について深掘りたいと思います。
そもそも決定木分類って?
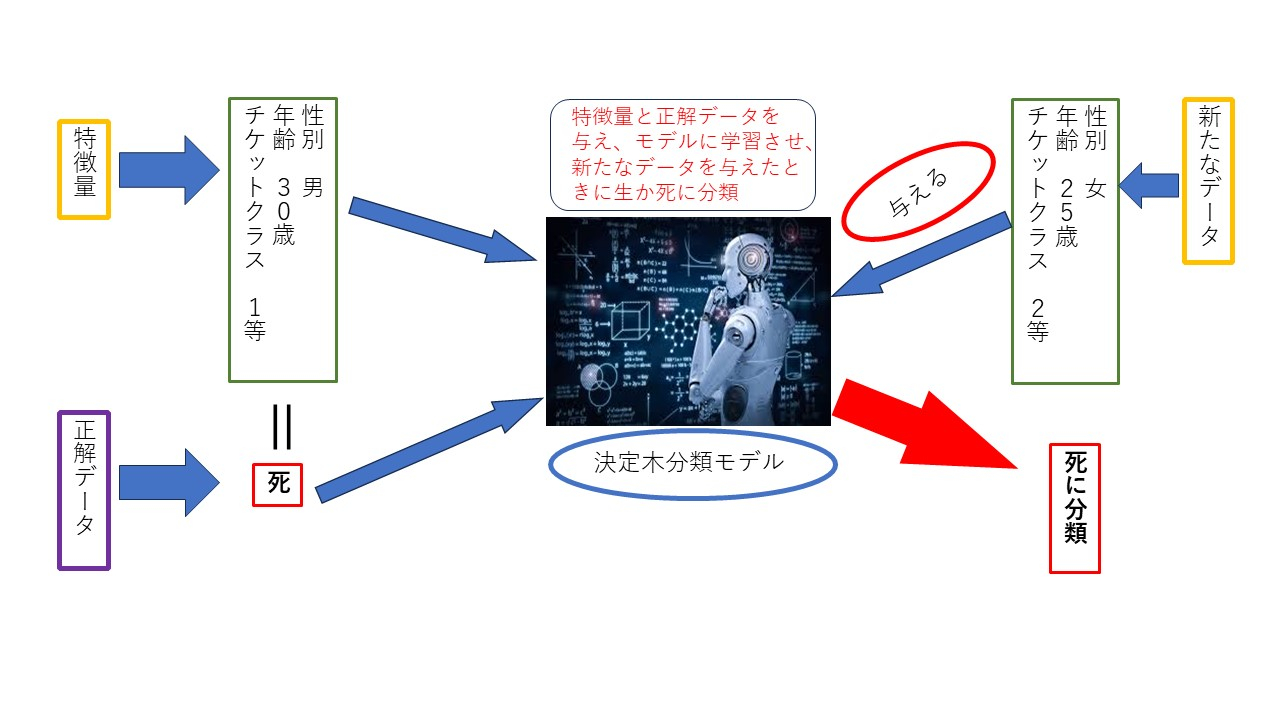
機械学習におけるデータ分析は大きく分けて教師あり学習・教師なし学習・強化学習の3つに別れ、教師あり学習には分類と回帰の手法があります。教師ありとは”答え”(正解データ)がある場合をいいます。例えば、今回タイタニック号沈没事故を例にすると、各乗客にはチケットクラス(1等、2等、3等)や年齢、性別、部屋番号、搭乗港等の特徴的な情報と生か死かという情報があります。これはデータ分析の視点で見ると、各乗客のこれらの特徴的な情報に対して、正あるいは死に振り分けられる、つまり正か死に分類ができると言え、これはつまり、各特徴的な情報と紐づけて正、死の2クラスの正解データに分類できます。
そして、教師あり学習とは、この正解データがあるデータでの学習を指します。じゃあ、具体的に何を学習するのかというと、上記の例でいうと、チケットクラス、年齢、性別、部屋番号、搭乗港といった特徴的な情報(特徴量)と正解データ(生か死か)を機械学習(具体的にPython言語では決定木分類モデルが標準で備えられており、これら特徴量と正解データをこのモデルに与えて学習させて、新たな特徴量をこのモデルに与えたときに、正あるいは死を予測します)させるのが、教師あり学習です。
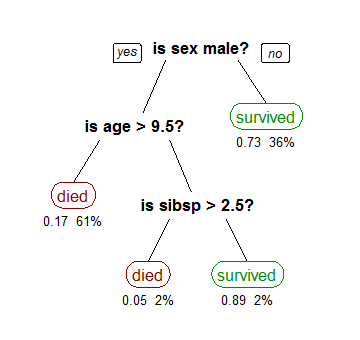
決定木は下図のように、各特徴量を分岐条件として正か死に分類していきます。まずは性別で男性か女性かで生か死かを分類し、次に年齢で分類しています。
このように、乗客の特徴的な情報をもとに生か死に分類しているツリー構造が決定木分類(分類木)です。
※回帰とは・・・例えば、とある企業の株価を予想する際に、株価が上がるか下がるかは分類だけど、株価がどんな値になるか、その数値を予測するのが回帰。つまり、答え(正解データ)が数値の場合は回帰で、乗客の生か死か、や株価が上がるか下がるかなどの数値ではないものが分類。(生か死かのように二択の分類を二値分類、3択以上の分類を多値分類といいます。)
では実際に機械学習における決定木分類は何を行っているのか?
それは先ほど例に挙げた乗客のチケットクラス(1等、2等、3等)や年齢、性別、部屋番号、搭乗港等の特徴的な情報を一つずつ条件分岐に使用します。そして、その条件分岐によって、枝分かれした次のノードで混在するクラス率(生と死の割合)を求め、そのクラス率が最も低くかった条件分岐を採用していきます。上の図では性別が一番最初に採用されていることから、性別で条件分岐した際に、枝分かれした次のノードにおける生と死の割合が最も低いということです。次に年齢、そしてSibSP(搭乗した兄弟や配偶者の総数)の順で生と死の混在率がだんだんと低くなっております。
このように条件をフィルターとして、生と死の混在率を少なくしていくのが、決定木分類のメカニズムです。
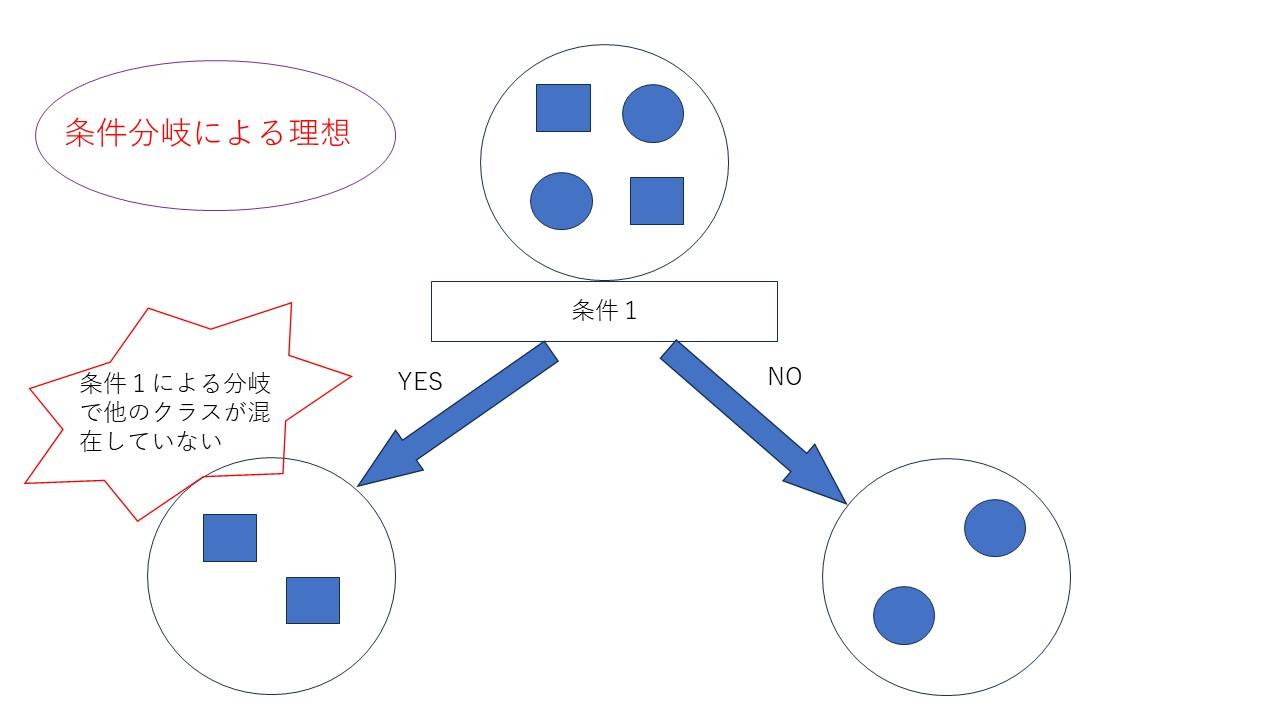
※要は下図のような、理想に近くなるような条件を探して、それを採用ていくのが、決定木分類です。
今回は分類の中でも決定木分類について記載しました。次回は回帰について深掘りたいなと思います。