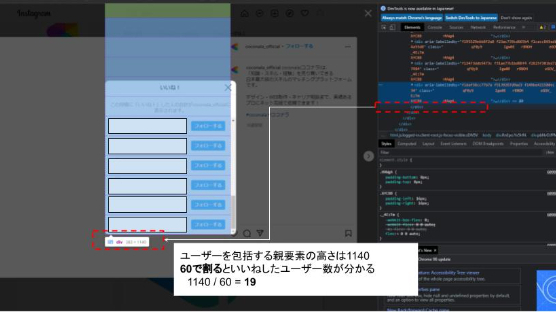
カスタム待機条件
関数 引数なしWebDriverWait(driver, 最大待機秒).until( lambda ドライバ: 条件)lamda内のd.find_element()は失敗してもエラーにならず 引数ありdef 関数(引数1, ...):
return lambda ドライバ: 条件WebDriverWait(driver, 最大待機秒).until(関数(引数1, ...))クラスclass クラス:
def __init__(self, 引数1, ...): self.引数1 = 引数1 ... def __call__(self, ドライバ): return 条件WebDriverWait(driver, 最大待機秒).until(クラス(引数1, ...))
0