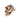Stable Diffusionで、できそうなこと(ココナラその2)
先日に続いて、Stable Diffusionでできそうなことその2。NovelAIで課金しなくても、ネット情報を漁りつつ、いろいろ小細工すると、なんとなくイラストっぽいものが出力されます。呪文を使って、文字から画像を生成することはもちろん、呪文を使って、画像を加工出力することもできます。例えば、これは自撮りした自分の顔をアプリ使って加工したものですが、これをベースに、「Cute girl,black hair, tsundere, moe, kawaii, beautiful,pixiv, niconico,fantasy scene, Illustrations drawn by xxx xxx, soft lighting」と呪文を唱えます。すると、こんな感じの画像ができたります。というのが、巷で問題になっている部分ですね。寄せたいイラストレーターさんの描き方、塗り方の特徴を学習させると、今段階ではなんとなく、それと似たような画風の画像が出力されちゃったりするわけです。ただ、問題は現時点ではまだ破綻箇所が多い(手足が増えたり)のと、呪文の作りこみが甘いと、表情の差分などが作りにくい点や、ポーズを変えた全身の画像などが、同じキャラクターにならないという点があると思います。頑張って、キャラクターの特徴を色々考えて、いっぱい盛り込んでも、「まだ」完璧にはならないわけです。なので、どうしても人の「手入れ」が必要になります。多分、今までココナラで発注してきた人は、描いてほしい項目を色々イラストレーターさんに言葉で伝えて、ラフ画を書いてもらい、そこから正式に制作を進めてもらうような感
0