はじめに
深層学習ベースの音声変換・音声合成モデルにおいて、Loss(損失関数)の挙動を正確に理解し制御することは、最終的な音声品質を左右する最重要事項のひとつである。RVC(Retrieval-based Voice Conversion)をはじめ、VITS、SoVITS、NaturalSpeech、Voiceboxといったアーキテクチャに共通して登場するloss_disc(識別器損失)、loss_gen(生成器損失)、loss_fm(特徴マッチング損失)、loss_mel(メルスペクトログラム損失)、loss_kl(KLダイバージェンス損失)は、それぞれ独自の数理的意味を持つ。
本稿では、これらのloss値が音声モデルの学習においていかなる役割を担い、どのような挙動が高品質な音声生成につながるかを、10の視点から解説する。本内容はRVCに限らず、VITS系列全般やGAN(敵対的生成ネットワーク)ベースの音声モデルに共通して適用できる普遍的な指針として活用されたい。
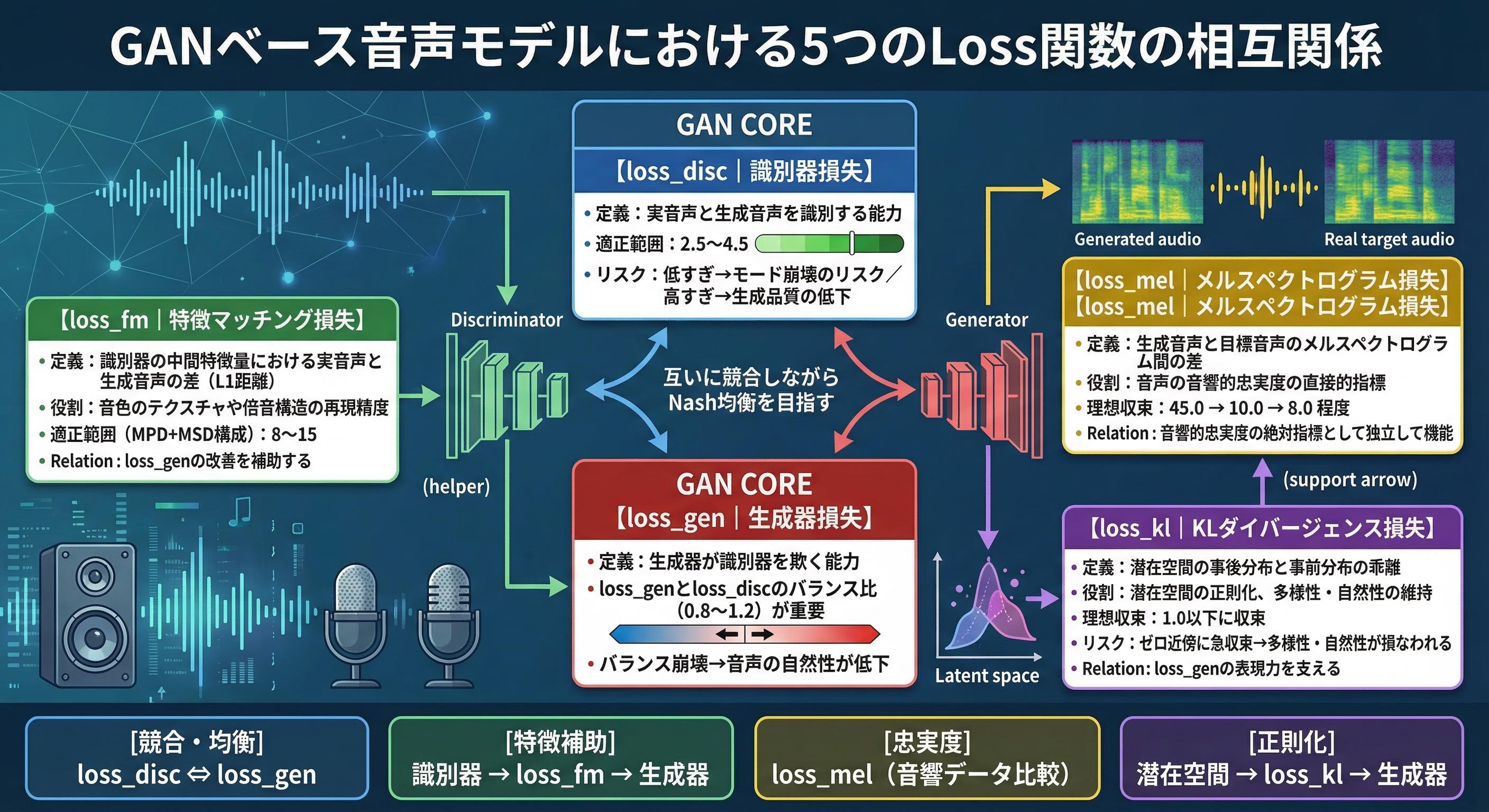
【画像①:各Loss関数の関係図(loss_disc/loss_gen/loss_fm/loss_mel/loss_klの相互関係を示す図解)】
各Loss関数の数理的意味と役割
loss_disc(Discriminator Loss)は、GAN学習における識別器(Discriminator)が実音声と生成音声をどれだけ正確に判別できるかを表す指標である。Multi-Period Discriminator(MPD)およびMulti-Scale Discriminator(MSD)を採用するVITS/RVC系アーキテクチャでは、loss_discが適切な範囲(概ね2.5〜4.5)で推移することが、生成器との健全な競合状態(Equilibrium)を維持する条件となる。loss_discが極端に低い場合は識別器が支配的となりモード崩壊のリスクが高まり、逆に過大であれば識別器が学習不足となり生成音声の品質向上が阻害される。
loss_gen(Generator Loss)は生成器が識別器を欺く能力を表す損失であり、Hinge loss形式またはLeast Squares GAN(LSGAN)形式で定式化されることが多い。loss_genの推移が安定せず振動を繰り返す場合、学習率の不均衡やBatchNormalization層の設定ミスが疑われる。loss_genとloss_discのバランス比(一般的にloss_gen/loss_disc ≈ 0.8〜1.2が理想)が崩れることで、生成音声の自然性が著しく低下する。
loss_fm(Feature Matching Loss)は、識別器の中間特徴量における実音声と生成音声の差をL1距離で計測するperceptual lossの一形態である。Kumar et al.(2019)のMelGANおよびKong et al.(2020)のHiFi-GANにより確立されたこの損失は、スペクトル的な細部の再現性に直接寄与する。loss_fmが高い場合は音色のテクスチャや倍音構造が不正確であることを示し、低すぎる値は過学習の可能性を示唆する。典型的な収束値は使用する識別器の層数や特徴量次元に依存し、MPD+MSD構成では8〜15程度が経験的に良好な範囲とされる。
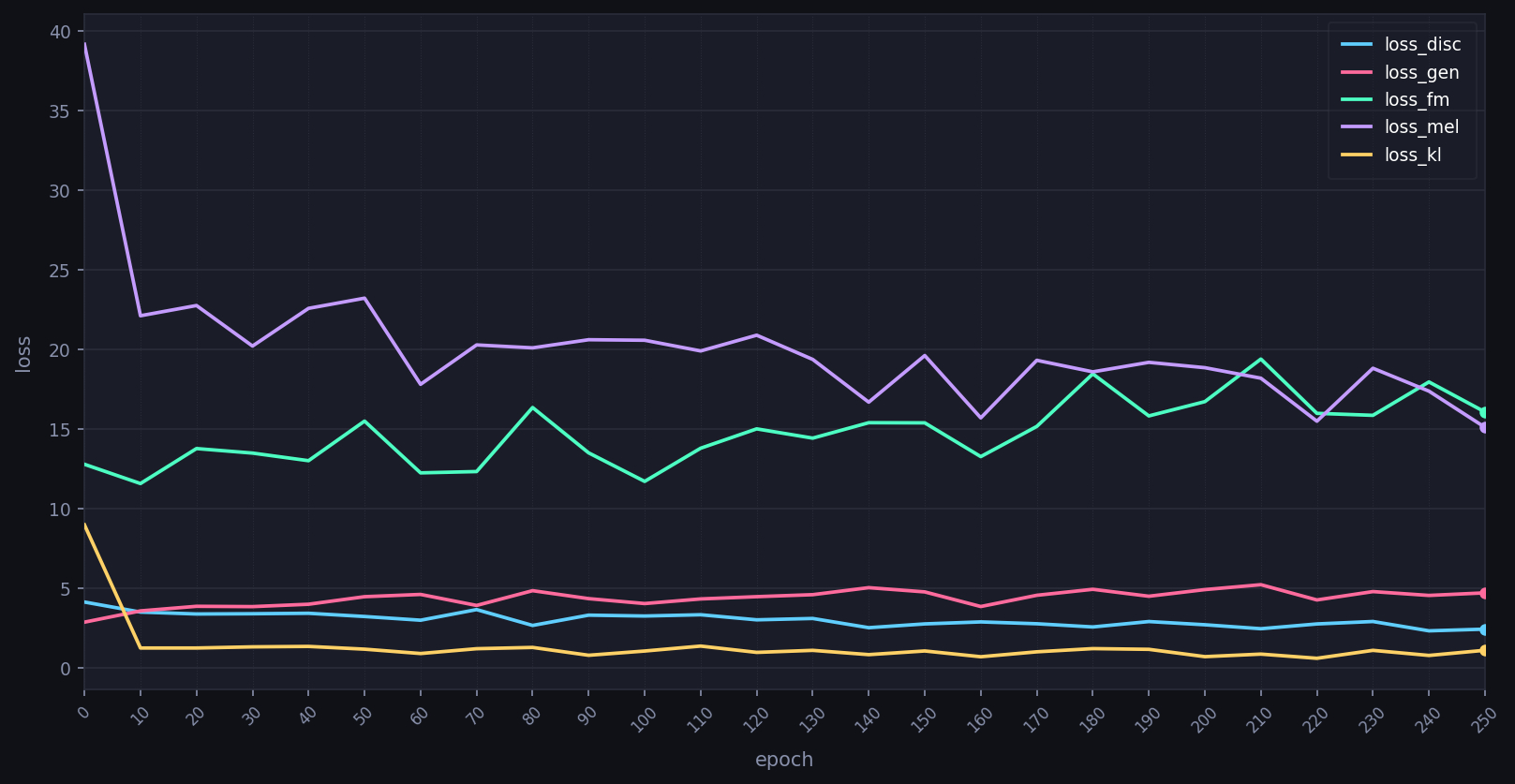
loss_mel(Mel-Spectrogram Loss)は、生成音声と目標音声のメルスペクトログラム間のL1またはL2損失であり、音声の音響的忠実度を定量化する最も直接的な指標である。Kim et al.(2021)のVITSでは45.0 → 10.0 → 8.0程度に収束することが示されており、loss_melの急激な低下は学習初期の音響特徴習得を示す。一方、loss_melがプラトーに達した後も高止まりする場合、メルフィルタバンクのパラメータ設定(FFTサイズ、ホップ長、フィルタ数)またはデータ前処理の問題が疑われる。
loss_kl(KL Divergence Loss)は変分推論(Variational Inference)フレームワーク内で潜在空間の事後分布q(z|x)と事前分布p(z)の乖離を計測するElbo(Evidence Lower BOund)の一項である。VITSおよびRVCの潜在空間正則化において、loss_klは学習初期に大きな値を示した後、潜在表現が正規化されるにつれ1.0以下に収束することが理想的である。loss_klが急激にゼロ近傍に収束する「KL Vanishing」現象は、潜在空間の表現力損失を招き音声の多様性・自然性を著しく損なう。
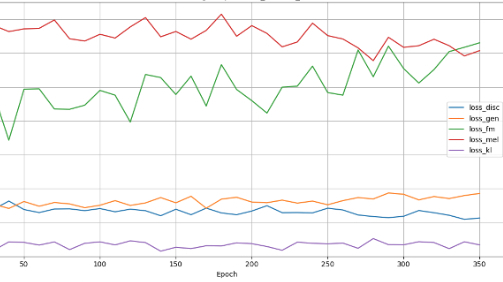
【画像②:各Lossの収束カーブ比較グラフ(縦軸loss値、横軸Epoch数のグラフイメージ)】
高品質な音声モデルを構築するための10の視点
【視点1】GAN Nash均衡の安定制御:loss_discとloss_genの動的バランシング
GAN学習の本質はNash均衡の追求であり、loss_discとloss_genが互いに競合しながら安定点に向かう過程が音声品質の向上と直結する。実践的には、識別器の学習ステップ数を生成器より1〜2回多く設定する「n_critic」戦略が有効であり、Wasserstein GANの勾配ペナルティ(WGAN-GP)の考え方を応用した学習安定化が推奨される。Epochごとにloss_disc / loss_genの比率をモニタリングし、比率が2.0を超えた場合は生成器の学習率を一時的に1.2〜1.5倍に引き上げる動的調整機構の実装が、安定した長期学習に不可欠である。
【視点2】loss_fmの重み係数最適化:知覚的音質とスペクトル整合性のトレードオフ
Feature Matching Lossの重み係数λ_fmは、多くのデフォルト実装では2.0に設定されているが、話者の音声特性によって最適値が異なる。倍音が豊富な歌声モデルではλ_fmを3.0〜4.0に引き上げることで高周波成分の再現精度が向上し、一方で発話モデルではλ_fm=1.5〜2.0が自然な音色と明瞭度のバランスを保つ傾向がある。Multi-Resolution STFT Loss(MR-STFT)をloss_fmと組み合わせることで、異なる時間-周波数解像度における音響特徴の整合性を同時に最適化できる。
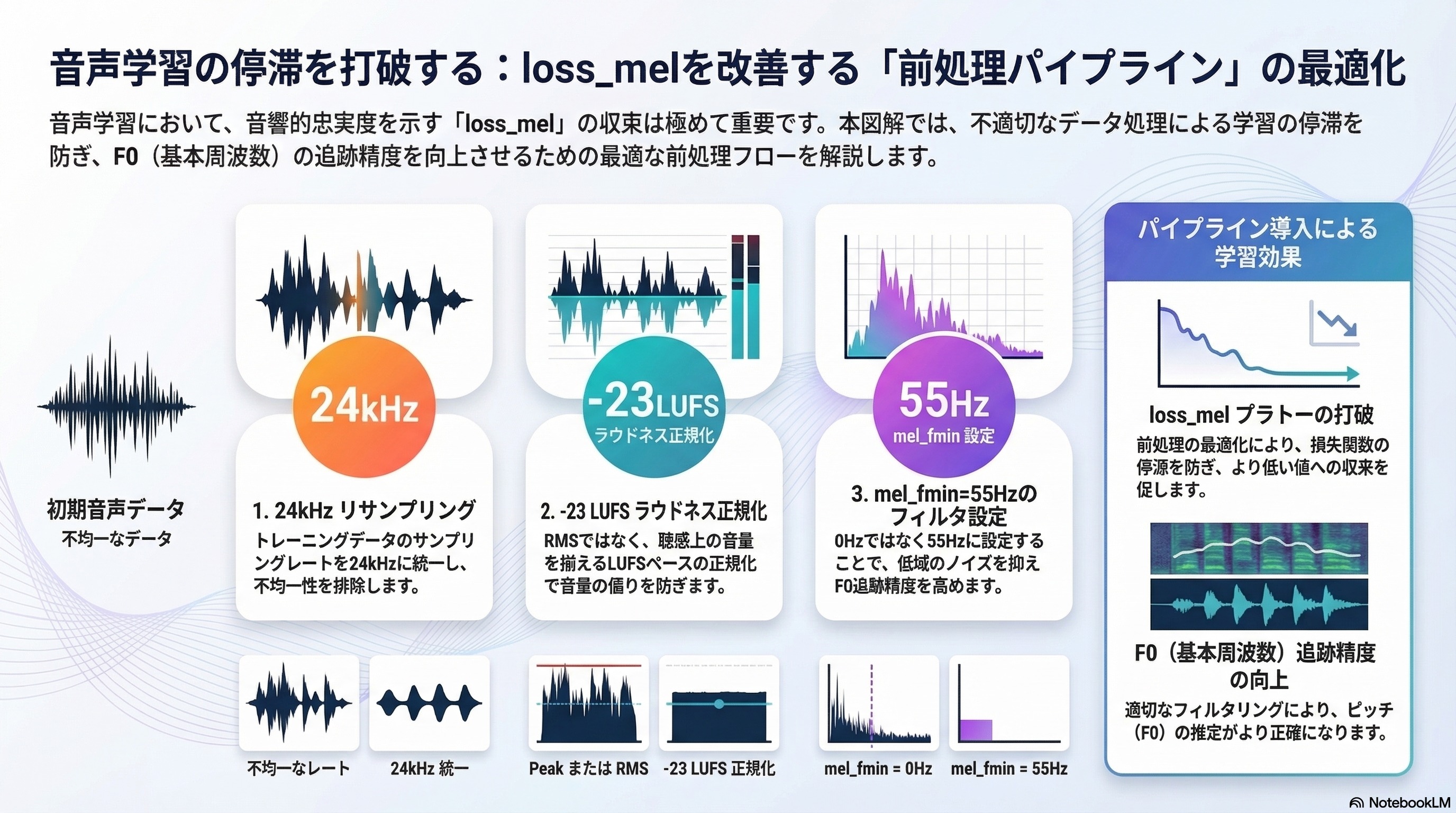
【視点3】loss_melのプラトー診断:音響前処理パイプラインの最適化
loss_melが早期にプラトーに達する主要因として、(1) トレーニングデータのサンプリングレート不均一性、(2) ノーマライゼーション手法の不適切さ(Peak vs. RMS normalization)、(3) フィルタバンクのfmin/fmax設定ミスが挙げられる。音声データは24kHz統一サンプリングレートへのリサンプリングとLuFS(Loudness Units relative to Full Scale)ベースのラウドネス正規化(-23 LUFS推奨)を事前処理として施すことが、loss_melの安定した収束を促す。また、mel_fmin=0HzよりもRVC標準のmel_fmin=55Hzのほうが基本周波数(F0)追跡精度に優れ、より低いloss_mel収束値が期待できる。
【画像③:音声前処理パイプラインのフロー図(リサンプリング→ノーマライゼーション→フィルタリングの流れ)】
【視点4】KL Vanishingの防止:β-VAEフレームワークとアニーリング戦略
KL Vanishing(loss_klの過早収束)を防ぐための最も効果的な手法はKLアニーリングである。具体的には、学習初期(Epoch 0〜50)においてloss_klの重み係数β_klを0.0から段階的に目標値(一般的に1.0)まで線形または余弦スケジュールで増大させるCyclical KL Annealingが推奨される。この手法により、Posterior Collapse(事後分布が事前分布に過早に一致する現象)を防ぎながら、潜在空間に意味のある話者情報・韻律情報を格納することが可能になる。β-VAEの観点からはβ=0.1〜0.5での学習開始が、音声変換モデルの潜在表現の豊かさと安定性の両立に有効である。
【視点5】学習率スケジューリングとloss収束の関係:Warm-up + Cosine Decay戦略
すべてのloss値の収束挙動は、学習率スケジューラの設計と不可分の関係にある。RVC/VITSではデフォルトでExponential LR Decay(γ=0.999)が採用されているが、より高度な手法として学習初期(Epoch 0〜10)に線形Warm-up(1e-5 → 2e-4)を行い、その後Cosine Annealing with Warm Restartsへ移行する複合スケジューラが推奨される。Warm-upフェーズを設けることで、学習序盤のloss_discの急激な低下(識別器の過支配)を防ぎ、すべてのloss項が協調的に収束するための初期条件が整う。また、Epoch 100以降にloss_melが再上昇する場合は、学習率が過大であることを示すサインとして学習率を0.5倍に調整する。
【視点6】トレーニングデータの品質エンジニアリング:SNR・話者純度・韻律多様性
すべてのloss値の最終収束水準は、トレーニングデータの品質に上限を設けられる。SNR(Signal-to-Noise Ratio)が30dB以上の音声データが全体の80%以上を占めることが、loss_mel・loss_fmの低収束値達成の前提条件である。話者純度(単一話者のみのデータ)が担保されることでloss_klの安定収束が促進され、異なるピッチレンジ・発話速度・感情状態を網羅した韻律的多様性を持つデータセットがモデルの汎化性能を高める。DNSMOS(Deep Noise Suppression Mean Opinion Score)スコアが3.5以上のデータのみを使用する自動品質フィルタリングパイプラインの構築が、実用的かつ効果的なデータエンジニアリングの指針となる。
【 画像④:データ品質フィルタリングの概念図(SNRや話者純度のチェックフロー)】
【視点7】Discriminatorアーキテクチャの高度化:MPD/MSD/MRD三段構成の優位性
識別器のアーキテクチャはloss_discおよびloss_fmの品質を直接規定する。従来のMPD(Multi-Period Discriminator)+MSD(Multi-Scale Discriminator)の2段構成に加え、Multi-Resolution Discriminator(MRD)を追加した3段構成(HiFi-GAN v3相当)を採用することで、人間の聴覚系が感知する周波数マスキング現象に対応した多角的な音質評価が可能になる。MRDはSTFTベースで動作するため、loss_fmの計算にメルスペクトログラムとは独立した特徴マッチング損失を追加でき、結果としてより低いloss_fm収束値と高いMOS(Mean Opinion Score)の相関が複数の研究で報告されている。
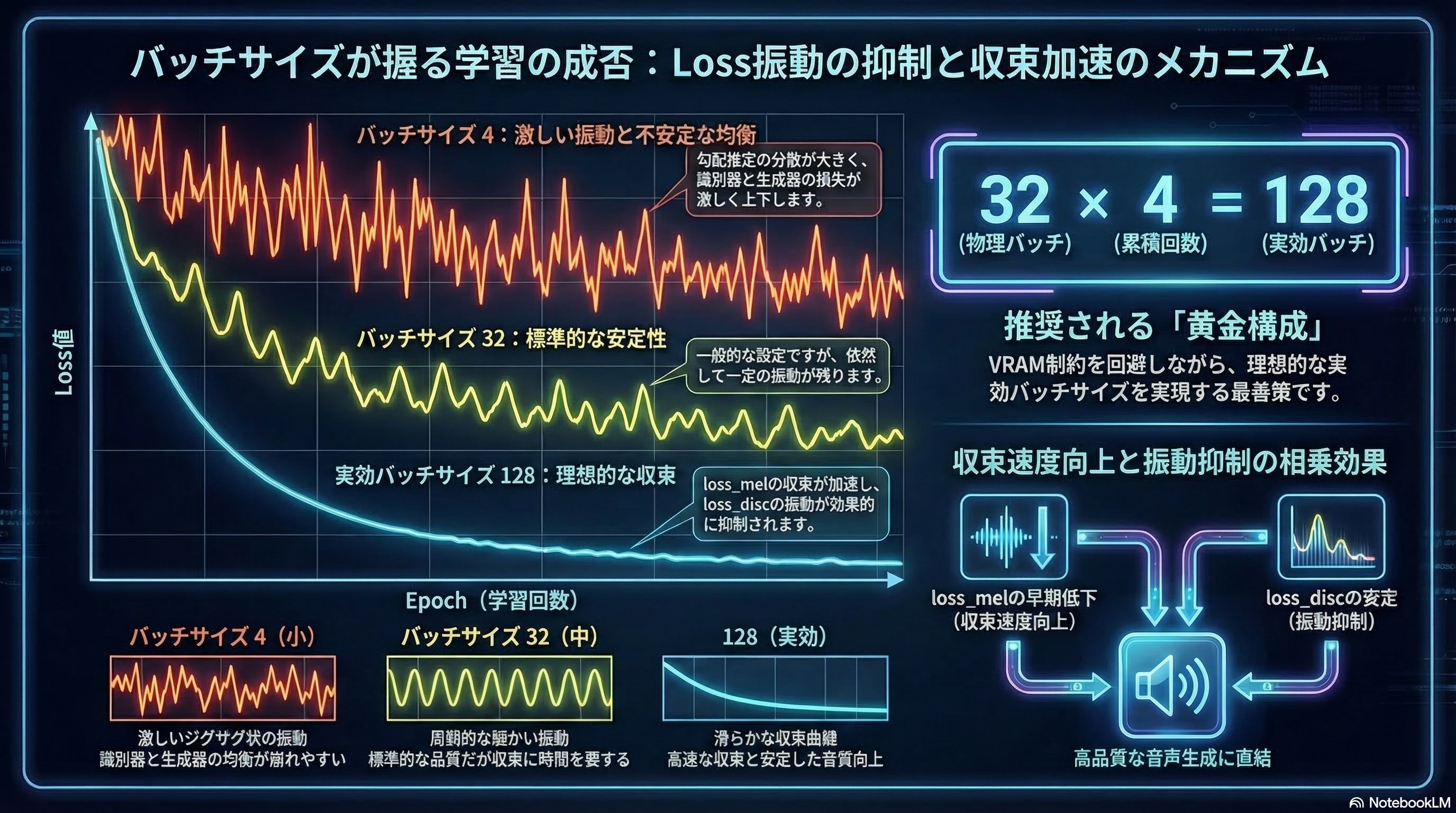
【視点8】Batch Size・勾配累積とloss安定性の数理的関係
loss値の振動(oscillation)はバッチサイズと強い相関を示す。GAN学習においてバッチサイズが小さい場合(4〜8)、勾配推定の分散が大きくなりloss_discとloss_genの振動が激化する。Linear Scaling Rule(学習率 ∝ バッチサイズ)に基づき、バッチサイズを倍増させる際は学習率も同比率で増大させることが理論上最適であるが、GAN学習ではこの法則が成立しにくいため、バッチサイズ32を基準とした勾配累積(gradient accumulation steps = 4)による実効バッチサイズ128の実現が、VRAM制約下での最善策として推奨される。実効バッチサイズの増大はloss_melの収束速度を向上させつつ、loss_discの振動を抑制する効果がある。
【画像:バッチサイズとloss振動の関係グラフ(バッチサイズ4/32/128比較の概念図)】
【視点9】Perceptual Evaluation指標との相関:MOSとloss値の非線形関係の理解
loss値の数値的改善と人間の知覚的音質評価(MOS)の間には非線形の関係が存在することを理解することが、モデル評価の根幹をなす。loss_melが10.0から8.0に低下しても、MOSが必ずしも比例して向上するわけではなく、逆にloss_discとloss_genのバランスが崩れた状態でloss_melのみが最小化された場合、音声は「のっぺりとした」テクスチャを持ち、知覚的な自然性が損なわれる。客観的評価としてUTMOS(Universal Text-to-Speech MOS Predictor)やSV(Speaker Verification)スコア(EER: Equal Error Rate)、また主観的評価のABX比較テストを定期的に(50 Epoch毎)実施し、loss値の推移と知覚的品質の相関を継続的に追跡することが不可欠である。
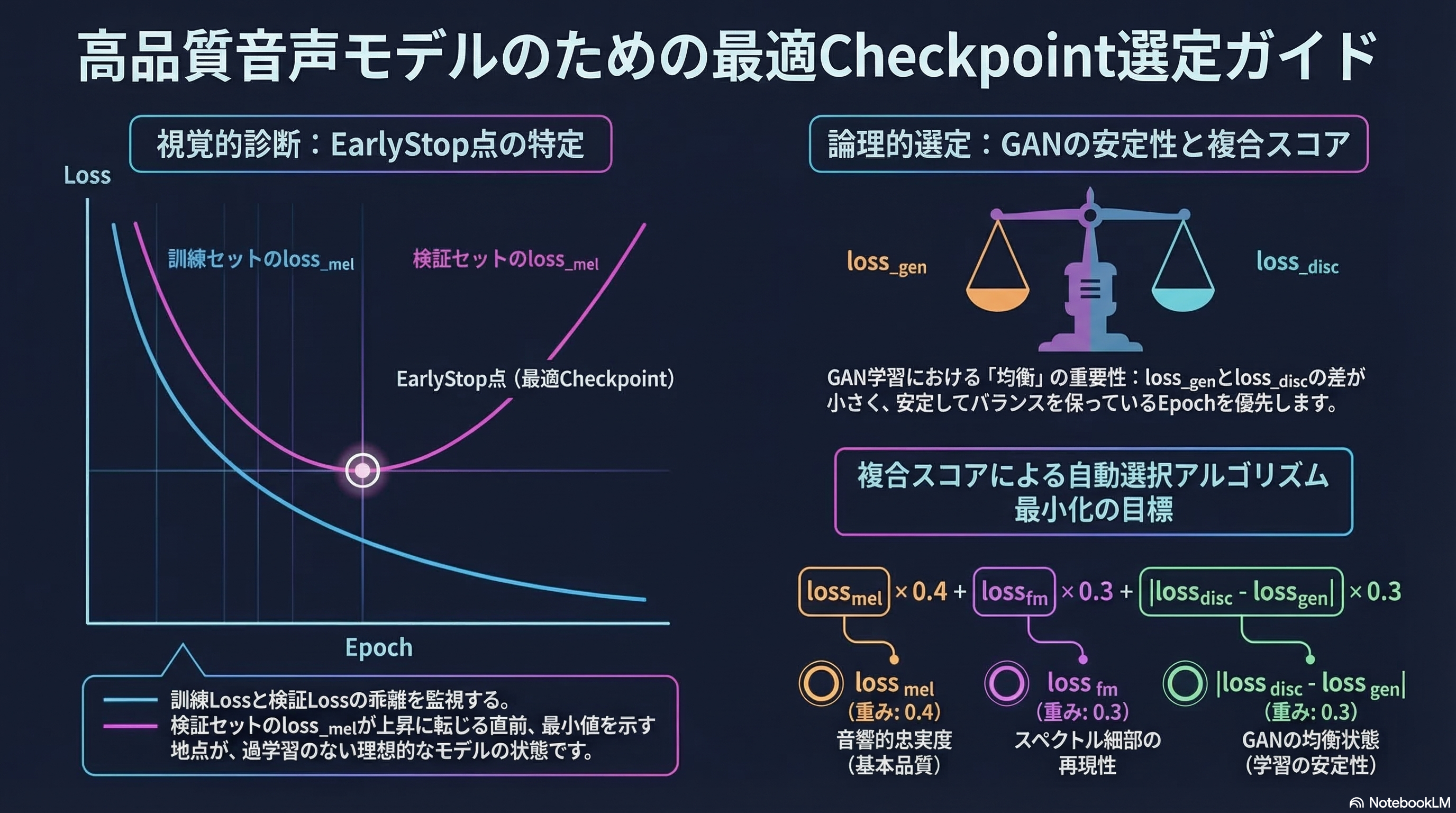
【視点10】Checkpoint選択戦略:loss値に基づく最適モデルの同定と過学習の検出
音声モデルの最終的な品質は、トレーニングを完了したモデルではなく、特定のCheckpointから最適なモデルを選択することで決定される。過学習の検出には検証セット(全データの5〜10%を別途確保)に対するloss_melの推移監視が最も信頼性が高く、訓練セットのloss_melが継続低下する一方で検証セットのloss_melが上昇し始めるEpoch(EarlyStop点)が最適Checkpointの目安となる。また、GAN学習特有の現象として、最終Epochのモデルが最も高品質とは限らず、むしろloss_genとloss_discが最も安定したバランスを示した中間Epochのモデルが知覚的品質で優る場合が多い。複合スコア(例:loss_mel × 0.4 + loss_fm × 0.3 + |loss_disc - loss_gen| × 0.3の最小化)に基づく自動Checkpoint選択アルゴリズムの実装が、高品質モデルの再現性ある取得を保証する。
【画像:Checkpoint選定の概念図(訓練loss vs 検証lossのEarlyStop点を示すグラフ)】
まとめ:Loss関数の統合的解釈と実践への橋渡し
音声モデルのloss値は、それぞれが独立した最適化目標を持ちながらも、互いに動的な相互作用を通じて音声品質を決定するシステムである。loss_discとloss_genの競合均衡が基盤となり、loss_fmがスペクトル細部の再現性を保証し、loss_melが音響的忠実度の絶対的指標として機能し、loss_klが潜在空間の豊かさを守護する—この4つの損失項の統合的なバランスこそが、高品質な音声モデルの実現を可能にする。
本稿で示した10の視点—Nash均衡の動的制御、λ_fmの最適化、前処理パイプラインの精緻化、KLアニーリング、複合学習率スケジューリング、データ品質エンジニアリング、識別器アーキテクチャの高度化、バッチサイズ戦略、知覚的評価との整合、そして最適Checkpointの選択—は、RVCに留まらず、あらゆるGANベースの音声合成・音声変換モデルに適用可能な普遍的フレームワークを構成する。
最終的に、音声モデルの学習とはloss値の数字を追いかける営みではなく、人間の聴覚認知の限界を研究し、それを数理的に近似しようとする学際的探求である。loss値の変化をナラティブとして読み解き、モデルが「何を学んでいるのか」を問い続ける研究者・エンジニアの姿勢こそが、次世代の音声技術を切り拓く最大の原動力となる。