今回初めてコンペにて銅メダルを獲得できたので、復習も兼ねて本コンペに対して、どういう分析を行ったかをざっくりですが、振り返りたいと思います。
(あくまで自分のやり方で銅メダルが獲得できただけであり、本コンペに対する模範解答ではありません)
今回のコンペの内容としては、旅行会社の顧客情報をもとに、顧客が旅行商品を契約するか否かの二値分類の教師あり学習でした。
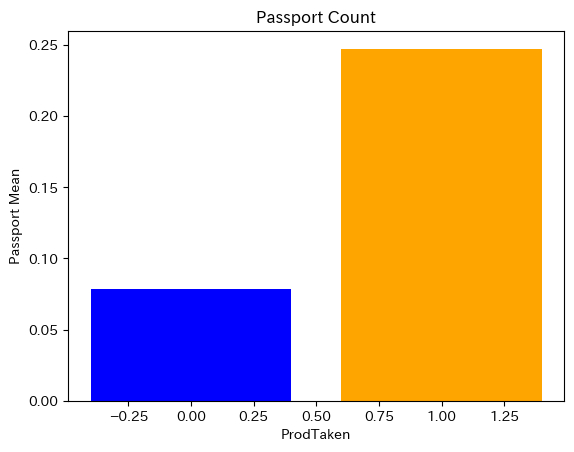
まず目的変数のProdTaken(成約が1,不成約が0)と各特徴量の関係性に着目しました。その中でPassportとProdTakenに注目すべき特徴がありました。(下図参照)
あきらかにパスポートを持っている人とそうでない人とで成約率に差があることが分かります。統計的にいうなら有意性がある(独立ではない)と言えます。
上図のように差があることが分かったわけですが、そのアプローチの経緯として、まずデータ分析においては全体データの把握や各変数間の関係性、データの分布性、欠損、外れ値等がないか確認をする「探索的データ分析(EDA)」が重要となってきます。
そして変数間の関係性については、量的変数(身長や体重など数値として意味をもつ変数)同士においては散布図、量的変数と質的変数(血液型や性別、職業などの文字列やパスポートの0、1など)には箱ひげ図、質的変数同士にはクロス集計などが有効的です。またデータ値の特性として、間隔尺度か比例尺
度なのかも重要になってきます。
年齢の特徴量の表記には一や1、五拾(ごじゅう)、歳や才など誤記も含め表記がバラバラなので、これらを数値に統一させる為、正規表現を使いました。また月収の50万や45000などの表記も一つに統一。
また、性別の特徴量においては、maleやF EMA LE など、表記がバラバラなだけじゃなく、文字列間の空白もばらばらだったので、文字列の統一はちょっと苦労しました。。
あとは、customer_info(顧客情報)のデータ値が「未婚車所持子供なし」など3つの情報が含まれていたことから、これらを分けて「Marital_status」、「Carownership」、「ChildrenCount」の3つの特徴量に分けて学習データに加えました。後に分かったのですが、lightgbmモデルで特徴量重要度を見てみると、この「Marital_status」が大きくスコアを上げてくれていました。
(今回のコンペは正規表現をやたら使ったような。。)
このほかに特徴量エンジニアリングとしては、年齢と月収はある程度比例するだろうなということから、これらの相互作用特徴量(掛け合わせ)や目的変数を重みとする「ProductPitched」のターゲットエンコーディング(この特徴量が決めてで入賞に!)を特徴量としました。ほかにもターゲットエンコーディングした特徴量も試したのですが、リークが発生し過学習気味になったので、やめました。
(リーク・・・本来予測するべき目的変数を重みとし、加味した特徴量を学習データに追加してモデルに学習させているため、学習データに対して異常に適合してしまい、その結果未知データに対するスコアが極端に低くなる(過学習))
モデルとしては先ほど述べたlightgbmモデルとcatboostモデルでのスコアを参考に、スコアが高い方のモデルに重みを大きくし、両モデルのアンサンブル学習したモデルにテストデータを与え、結果を予測しました。
※catboostモデルを使った理由としては、質的データが多いデータに対して堅牢なモデルであると言われていたからです。
今回はlightgbmとcatboostのアンサンブル学習で予測を行ったわけですが、案件にもよるかとは思うけど、実際のビジネスモデルではいいから早く結果を出してくれという声が多く、単体のモデルを使う場合も割とあるので、自分の中ではアンサンブルやスタッキングはコンペ用なのかなとか思ったりしてます。