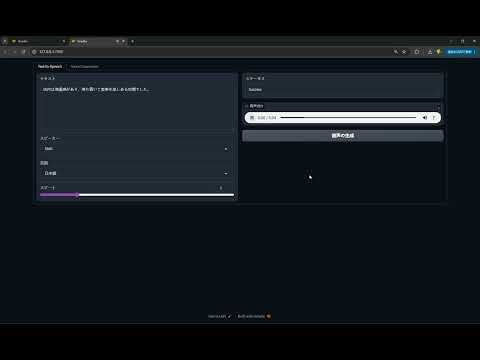
TTSモデル作成サービスは、お客様からご提供いただいた大切な音声データをもとに、話者の声の特徴を丁寧に学習したオリジナル音声モデルをお作りします。
自然で聞き取りやすい声がいつでも生成できるため、動画制作やナレーション、教材づくりなど、さまざまな場面で活躍します。録音の手間を減らしながら、品質のそろった音声を何度でも作れるのが大きな魅力です。お客様の声を活かした“あなただけのTTS”で、もっと便利で楽しい音声コンテンツ制作をお手伝いします。
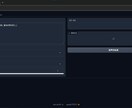
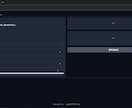
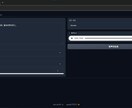
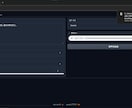
また、APIとしてpythonスクリプトから呼び出す環境(社内環境で音声作成サーバーとして、外部からのアクセスは不可)の構築もお手伝えます。
※パフォーマンス(下記CPU、メモリはあくまでも目安とする)について、
NVIDIAのGPUカードがない場合、5.2秒で4秒の音声データが作成できる(i5-5300U 2.3GHz/12GB memory)
NVIDIAのGPUカード(GTX1660以上)を利用する場合、アプリ起動後の初回の変換は2.2秒で4秒 音声データが作成できる(ryzen 5700G 3.8GHz/ 96GB memory )、2回目以降は1秒で4秒 音声データが作成できる
音声は日本語で、こちらから指定の文書を読み上げで15~20分の音声データをいただく、もしくは、お客様選定の文章で元のテキストをいただく必要です。
録音の際は、発音を正確に、そして聞き取りやすく自然な声で話してください。また、認識に影響を与えるような背景雑音が入らないよう、静かな環境での収録をお願いいたします。
実行環境は事前にPythonのインストールが必要(実行手順書を提供する)で、GPUなしの場合でも200MB以上の空き容量が必要。モデルファイルは300-400MBのサイズで、ご利用の環境に空き容量があるかを事前にご確認いただく。
環境の構築もお手伝えしますが、オプション料金として上記をご確認ください。