機械学習は、高次の交互作用を無視しますので、現場のプロの想定内になり、そんな事知ってるよ。と言われます。(3次の交互作用くらいまでなら人でも学習します。)
深層学習は、高次の交互作用を活用しますので、想定外の結果になり、現場のプロを驚かせ、AutoMLを使っているライバルとの差別化が可能です。
ライバルに勝つには、多目的最適化モデルが必要です。
品質とコスト等
単目的のモデルならば、AutoMLで十分です。
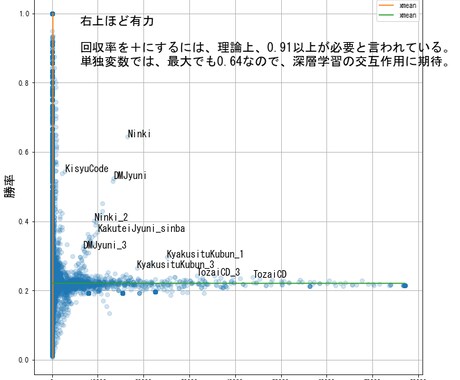
データ分析の三流は、綺麗な層別グラフを書いて、無限試行すれば、この場合の確率が高いで終わり。二流は、的中率の高い汎化モデルを作って終わり。一流は、品質とコスト等の相反する目的の最適解を見つけます。
AutoMLの時代に、機械学習だけを勉強されてもライバルに勝てません。
勝つためには、深層学習でモデルを作り、実験計画法等でシミュレーション、介入効果の出る変数を探索するモデルベース開発が必要です。
最近は、ハードの低価格化で、数十万回の机上実験が可能になり、
目標値を達成する打ち手の発見が可能になってきました。
(月2万程度で、並列計算が40個可能)
他のセールスポイント
1.深層学習の利点である特徴量エンジニアリング不要、が活かせ安価です。
何もチューニングせず、データ分析コンテストの中位に入ってきます。
2.言語、カテゴリデータ混在が得意で、数値ベクトル化が安価に可能です。
製造、実験等の条件4M(材料、装置、方法、人)は、ほとんどがカテゴリデータです。
3.フリーソフトのPyTorch_Tabularを使いますので安価です。
1.お見積りは、経理委託会社からの発行が可能です。(インボイス対応済)
2.フリーソフトのPyTorch_Tabularのため、どこまで変数が扱えるか?トライしてみないと不明です。(トライ費用は無料です。分析結果報告はなし。)
実績:colab Pro 62GBの場合
1.変数の数 約1000個
2.カテゴリ変数のカテゴリ数 約500個/変数
3.データ数が多い場合は、実験計画法で、反事実を考慮しリサンプリングします。
(一般的な乱数サンプリングでは、少数の反事実データを逃してしまう可能性があります。)
3.googleドライブにアップできないデータは、要相談。
案1)GPU搭載パソコンをご支給。ネットにアクセス不可。USB不可。
案2)御社の敷地内で、御社のパソコンで解析(10万/日)
案3)分析手法の手順のみリモートで講習(10万/日、ノウハウ料を含む)