「PDFの中の文字を検索したいのに、できなくて困った…」そんな経験はありませんか? 画像として保存されたPDFは、OCRで文字を認識できず、検索やコピーができないことがあります。私自身もこの不便さを何度も体験し、「必要な情報がすぐに探せない」「資料の再利用ができない」といったストレスを感じてきました。
本サービスでは、そのような 文字認識できないPDFをOCR処理によって文字認識可能なPDFへ変換するためのPythonプログラムを提供いたします。
#### 提供内容
- Pythonソースコード一式
・OCR処理を行い、文字認識可能なPDFを生成
・複数ページのPDFにも対応
・日本語・英語を含む多言語に対応可能(Tesseract OCR利用)
- 基本的な使い方マニュアル(README形式)
・環境構築方法(Python、必要ライブラリのインストール)
・プログラムの実行手順
・出力PDFの確認方法
#### 基本仕様
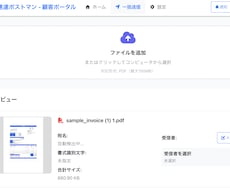
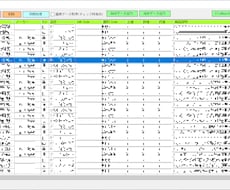
・GUIで対象となるPDFが入っているフォルダを選択(階層構造対応。PDF以外のファイルが混ざっていても問題ありません)
・出力先を指定
#### こんな方におすすめ
- PDF内の文字を検索・コピー・編集したい方
- 書類の電子化を効率化したい方
- 研究資料や業務文書を扱う際にOCRを導入したい方
- 自分の環境で動かせるプログラムを手元に残したい方
#### ご利用のメリット
- AIなどで検索可能なPDFに変換できるため、必要な情報をすぐに探せます
- コピー&ペーストが可能になり、資料作成やデータ整理が効率化
- ソースコード提供のため、用途に合わせてカスタマイズ可能
- 外部サービスに依存せず、ローカル環境で安全に処理可能
#### 注意事項
- 本サービスは ソースコードの提供 が中心です。実行環境の構築はご自身で行っていただきます。
- OCRの精度は元PDFの画質や文字フォントに依存します。完全な認識精度を保証するものではありません。
- ご不明点や導入に関するご質問は、何度でもお気軽にご相談ください。
・ご希望の仕様があれば別途ご相談ください。追加料金はいただきません。
・手書き文字や識別困難なもの等、データによってはうまく変換ができない可能性がありますので、予めご了承ください。
・GUIの配置、仕様などご希望の場合は別途ご相談ください。あまり凝ったデザインは難しですが、できる限りご要望にお応えいたします。