政府広報の総合窓口にて公開されている患者統計(令和5年)を分析します。この情報は大きなデータベースを規定された切り口で集計されたデータベースの形でダウンロードすることができます。様々な切り口がある中で今回は「受療率(人口10万対),入院-外来・施設の種類 × 傷病分類 × 都道府県別」というデータベースを分析します。
このデータベースからは都道府県別の受診率が分析できます。例えば「循環器系の疾患」での受診率が多い県はどこかと言うことを特定することができます。ただ、「受診率」とありますが、実際に循環器疾患がある人のうちの受診している方々の数を示すものではなく、あくまでも「循環器系の疾患で受診した患者数(対10万人)」を示しているだけです(受診していない循環器疾患患者の数を正確に把握することは極めて困難と思われます)。
このため、この結果から導き出せる結論は下記にとどまると想定しています。
・各県によって様々な疾患の受診者割合に差が有るのか
・入院/外来の比に各県のばらつきはあるか
⇒それに対する「医師数や診療科数、病床数が十分か?」を示す元データにすることは可能です。なお、「受診者数が多い=患者数が多い」なのかもしれませんが、受診啓蒙が進んでいれば受診者数も多くなるので、行政の広報活動の検証材料とすることも可能かもしれません。
また、同データベースでは年齢別のデータも取得できるため、受診年齢層と受診科の相関なども示せるかもしれません。
この辺りも視野に入れつつ、とりあえず分析を始めてみます。
データベースの確認
早速ダウンロードしてみます。
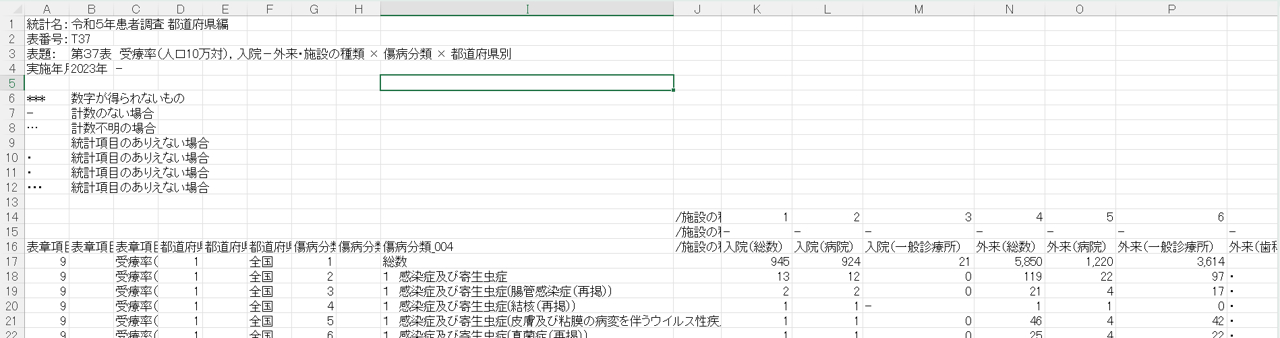
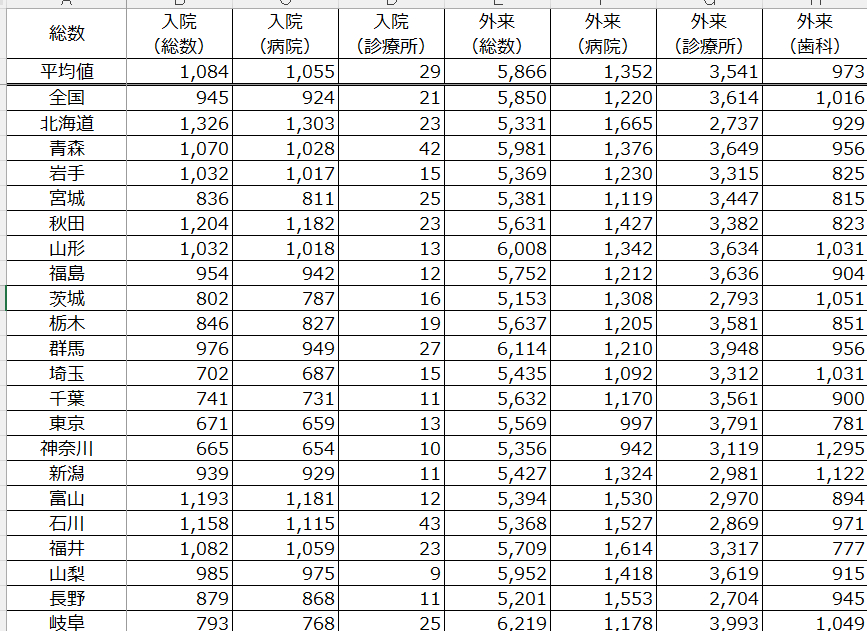
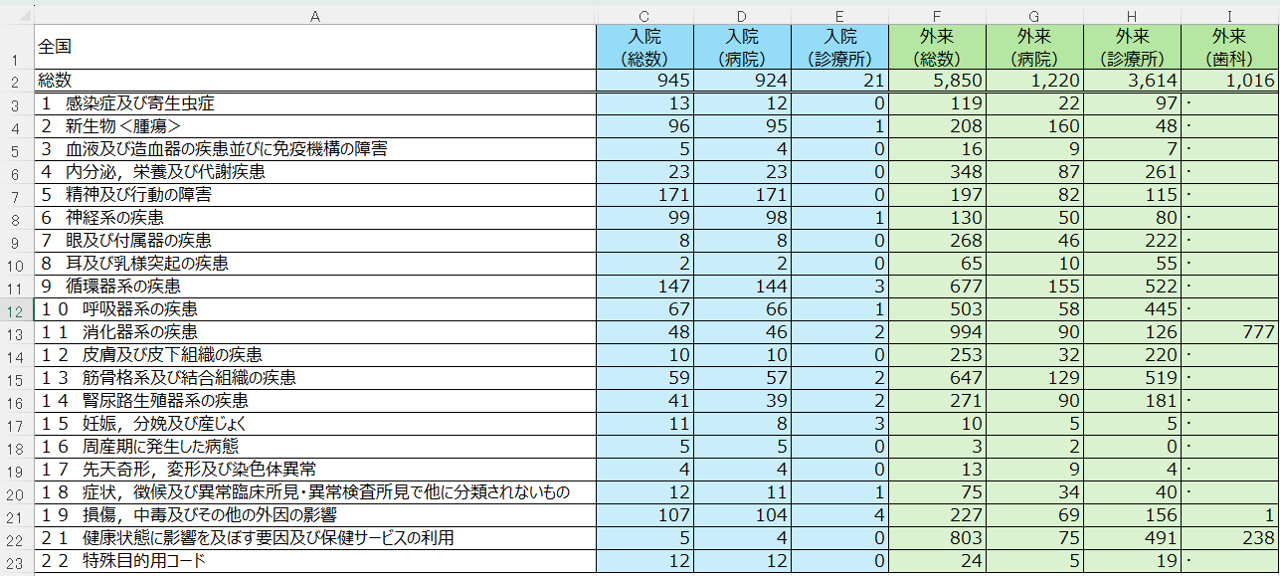
見やすくするために事前に幅を調整していますが、こんな感じのデータベースでした。CSVデータなのでセルの結合はなく、このまま使えそうです。F列の項目数はは都道府県+全国なので48種類であることが想定できますが、I列の項目数がとても気になります。
I列を選択して「重複を削除」処理をするし、Ctrl+Shift+↓で最終行を確認すると60項目ある事がわかりました。ちょっと多いので整理したいところです。なお、A16セルをクリックしてCtrl+Shift+↓をすると最終行は2,896行となったので、データの約2900行ということがわかりました。
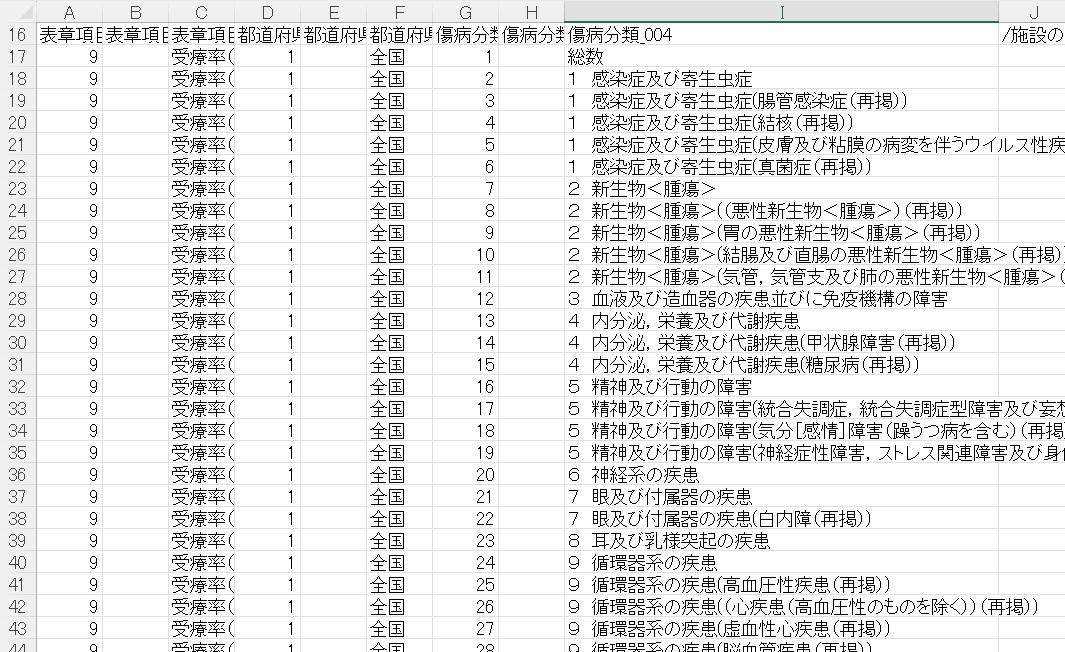
I列データの構造を見てみます。
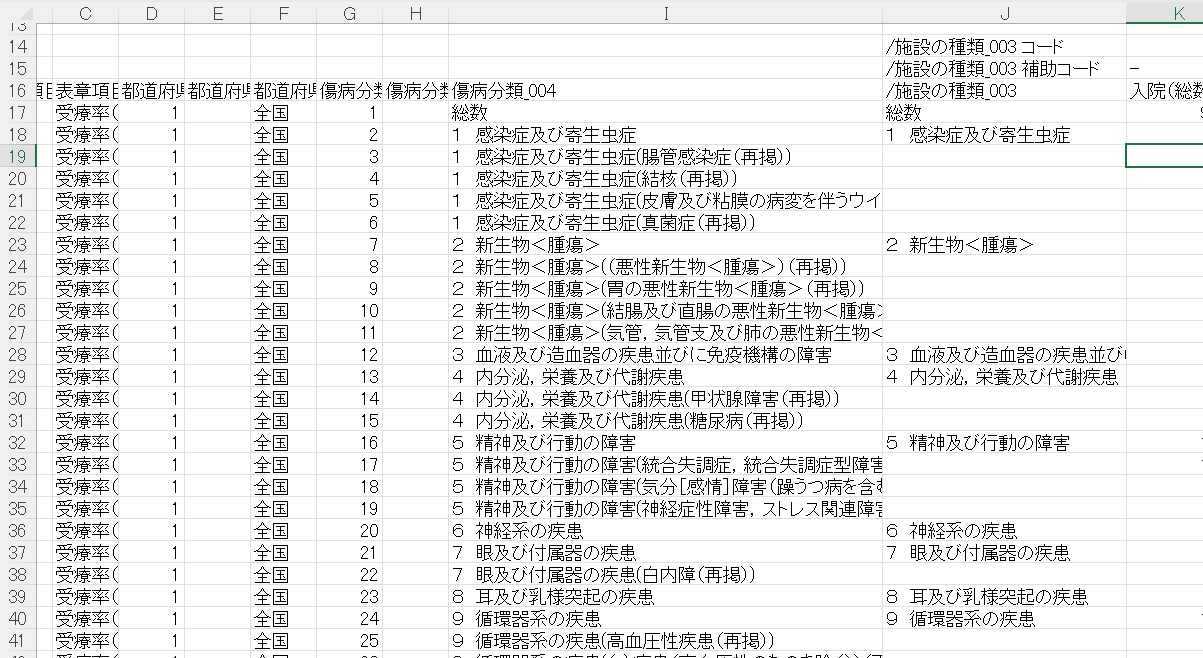
こんな構造になっていました。「1 感染症及び寄生虫数」という大項目と「1 感染症及び寄生虫数(腸管感染症(再掲))という小項目が混在されています。番号をみると「22項目+総数」で23項目あるようです。これを大項目と小項目にわければ、全体像と各疾患の内訳を分析しやすくなりそうなので、加工していきます。
このシートをシート2にコピペして貼付先になるデータベース(DBタブ)を作っていきます。
まずは大項目のみを取り出していきます。
大項目のデータは①各項目の一番上にありますので、「1」が「2」に代わったセルのみを取り出すことで大項目のみを選別することができます。
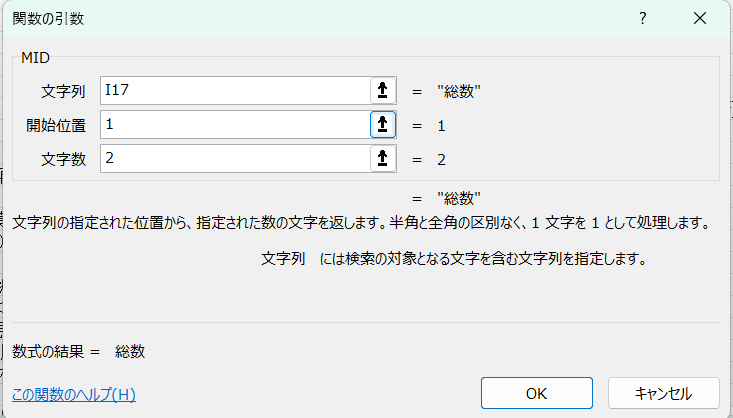
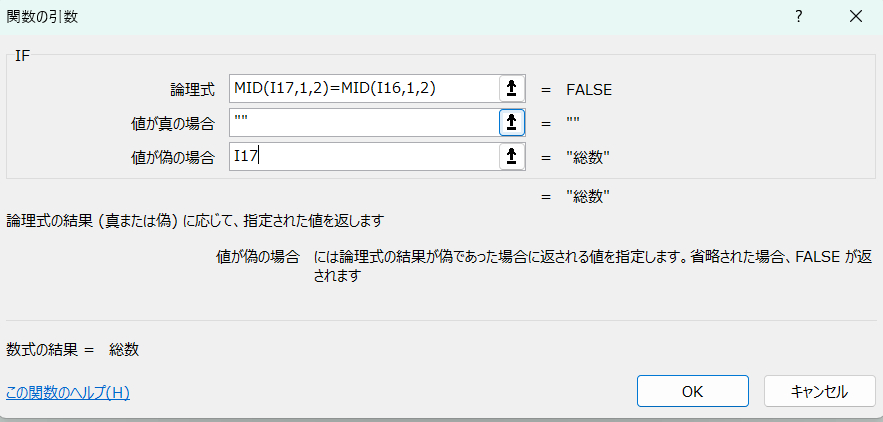
IF(MID(I17,1,2)=MID(I16,1,2),"",I17)
【MID関数】
MID関数は「文字列」から「指定の文字(この場合は一つ目から2文字)を抽出する関数です。I17には「総数」という文字があることがわかります。
これを条件に組んだIF関数が上記です。翻訳すると「このセル(I17セル)の最初の2文字」と「前のセル(I16セル)の最初の2文字」が同じなら空白、違っていたら「このセル(I17セル)」の文字を反映させるという式になります。大分類が変わる時は文字列の最初の数字が「1」〜「23」まで変わるのでこれで大項目のみを抽出することができます(J列に反映されました)。
次にこれをデータベース化するためにJ列の空欄(19~22行目等)を埋めていきます。Kに列を追加してこれを反映させていきます。
IF(J18="",K17,I18)
J18が空欄なら、K17を反映させ文字列があれば、その文字列を反映させるという式です
このシートの列を後で分析しやすいように加工(列の入れ替え、余計な行の削除など)をしてデータベースの完成となります。
このデータベースを元に分析をしていきます。
データ分析(都道府県別)
まずは「総数」で各都道府県に差が有るのかを見てみようと思います。食文化や気候などの違いにより差がでてくるかもしれませんし、令和5年なのでコロナ禍の影響による違いもあるかもしれません。
下記の外枠を作って、ここに対応するデータを反映させていきます。
ちなみにこの集計表はA1セル「総数」を「感染症及び寄生虫症」等の別の疾病分類をプルダウンで選択すれば、その疾病分類のデータを表示することができる仕様にしています。
INDEX(DB!E:E,MATCH($A3&$A$1,DB!$B:$B&DB!$C:$C,0))
これはB3セルの式です。INDEX関数とマッチ関数を組み合わせています。詳細は下記ブログをご参照ください。
すると少し面白いデータが出てきました。
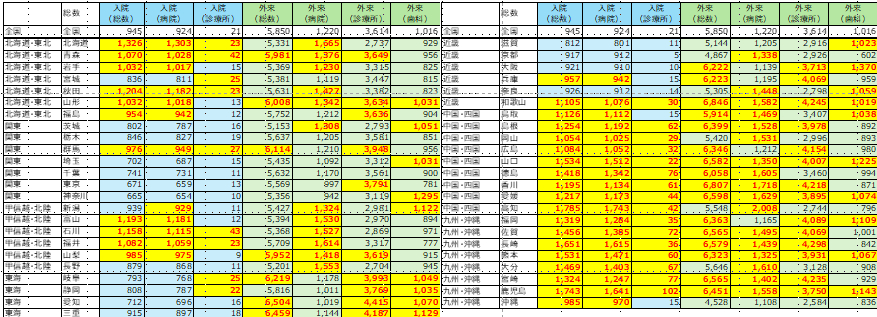
関東が低く、東北が平均並みが多いというだけでなく、北陸3県が共通して高い。つまり県別の違いではなく、地域別の違いがあるかもしれません。
地域差の影響も確認するため、日本医師会のブロックをデータベースに加えて「全国」よりも多い地区に色を付けてみました。
こうして作成した地区別の集計は下記となります。
全体的には「西高東低」というか、「関東」「東海」「近畿」といった都市圏を抱えるブロックが少ないように見えます。また、気になっていた北陸3県を含む「甲信越・北陸」は両極化しているようにも見えます。また、宮城県、群馬県、兵庫県などがそれぞれのブロックとは異なるデータになっています。
ブロック別の集計で改めて確認してみます。
ブロック別の数字は下記計算式で算出しています。
SUMIF($A$3:$A$50,$L3,D$3:D$50)/COUNTIF($A$3:$A$50,$L3)
セルの位置が微妙なので文字でします。
SUMIF:検索範囲(地区が含まれる列)、条件(それぞれの地区)、集計範囲(入院総数が含まれる列)
で計算した地区別の合計を
COUNTIF:検索範囲(地区が含まれる列)、条件(それぞれの地区)で計算した地区の構成数で割り算をしています。
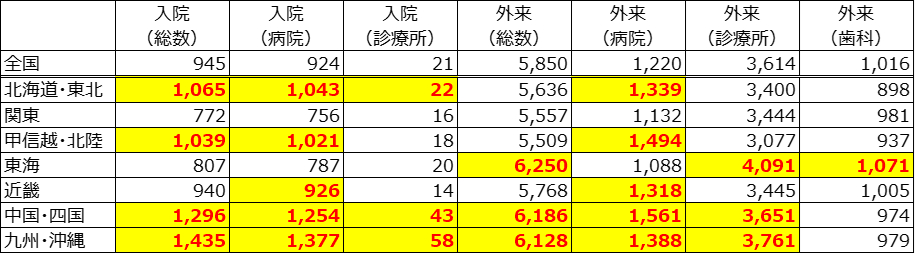
条件付書式で黄色色付けしたセルが全国平均よりも多い地区となります。
この結果から下記がを読み取ることができる。
・入院・外来ともに多いブロックは「中国・四国」と「九州・沖縄」で全項目が多い。特に診療所外来は全国の2倍の患者数となっている。
・病院入院が多いブロックは病院外来も多いが、診療所入院が多いブロックの診療所外来はブロックによってまちまち。
・「関東」は全項目が全国より低い
一方、北陸3県の傾向、宮城・群馬・兵庫の独自性などが見えなくなってしまいましたので、ブロック別の分析は「全体像の把握」という役割として分析をここまでにします。
都道府県別の分析はA1セルの疾病分類を変えれば、その疾病のデータが表示されますので、疾病ごとの分析が可能です。
その選択すべき疾病を確認するために疾病別の分析表も作成します。
データ分析(疾患別)
同じデータベースから疾患別の分析表を作成するために、下記のような枠組みで上記と同じ方法で各データを反映させると下記となりました。
(今回は最初から色分けしてみました)
前から気になっていた外来(歯科)は「消化器系の疾患」と「健康状態に影響を及ぼす要因及び保険サービスの利用」に含まれていました。データベースをみると、虫歯や歯周病、差し歯などが該当するようです。
これは「消化器系の疾患」を誤認する要因となりかねないので注意が必要ですが、逆に「歯科診療の地域特性などを把握する」ためには有効なデータとなるかもしれません。
「15」と「16」つまり周産期関連の受診率は驚くほど少ないことがわかります。いわゆる少子化問題はこのデータでもその深刻さが示されています。
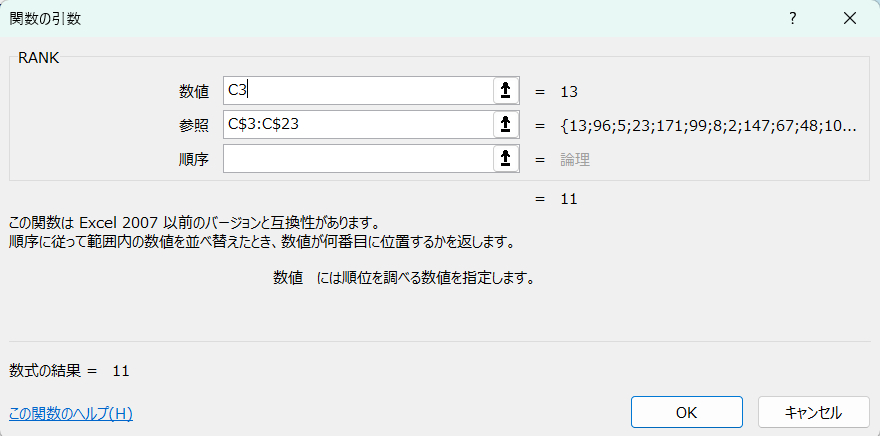
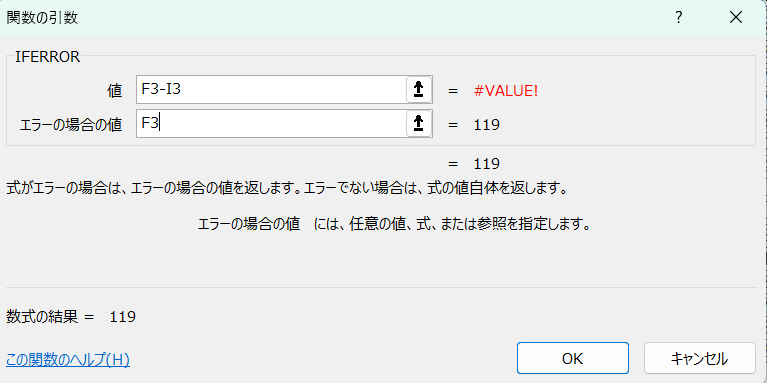
このままではわかりにくいので、ランキング形式にしました(RANK関数)。また消化器疾患の誤認を防ぐため、歯科受診を除いて算出しました(IFERROR関数)。
RANK(C3,C$3:C$23)
範囲内(参照:この場合はC3セル〜C23セル)の中でセルの値(数値:この場合はC3セルの数値)が何番目かを示します。順序は空白にすると降順(範囲内で最も大きい数値は1番)となります。
なお、C$3して行数を固定することによって、ドラッグコピーで別セルでも対応できるようにしてあります。
IFERROR(F3-I3,F3)
このデータベースでは空欄に「・」と言う文字列が入っていて、引算をするとエラー(#VALUE!)が表示されてしまいます。IFERROR関数はエラーが表示された時に表示する値や文字を指定することができます。これを応用すれば、エラーが出れば空白:IFERROR(計算式、””)とすることもできます。
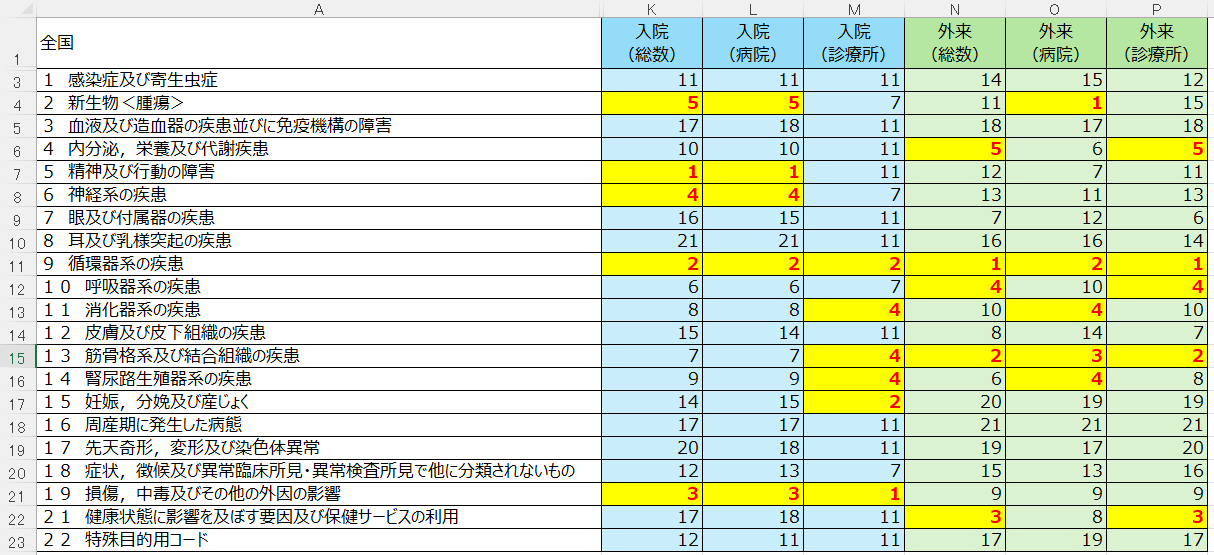
上記資料に条件付き書式で上位5つを色づけると下記になります。
想定通り全国的に見ると循環器疾患で受診している患者さんが一番多い事がデータでも示されました。
この分析結果からは様々なことがわかります。
例)
「腫瘍」は病院外来数で都道府県比較等を行うべきかもしれない。
「精神疾患」「骨折等の外科疾患」は病院入院数で判断すべきかもしれない。
「周産期医療」については診療所入院数で調査すべきかもしれない
・・・
もう少し細かく見てみます。
冒頭に示したようにこの傷病分類は大分類です。例えば「循環器系の疾患」は「高血圧性疾患」「心疾患」「虚血性心疾患」「脳血管疾患」についてのデータを抽出することができます。これにより「循環器内科」「脳神経外科」などの状況を推測することも可能です。これを分析表にしてみます。
こうすると、下記のようなことがわかってきます
「高血圧性疾患」患者の多くは診療所で外来受診しているが、それ以外の疾患については病院の外来受診をしている事も多い。
「高血圧性疾患」の確認は入院数よりも外来数の方が適しているが、「脳血管疾患」については入院・外来の両方の受診数を考慮すべきかもしれない。
まとめ
この分析は下記を想定してとりあえず始めてみました。
・各県によって様々な疾患の受診者割合に差が有るのか
・入院/外来の比に各県のばらつきはあるか
実際に分析してみると、受診率は西高東低の可能性があり、入院/外来の比率は「傷病分類の小項目」つまり疾患の特性によって異なる可能性があることがわかりました。
このデータベースを元に各都道府県や疾患ごとの特性を把握することができることがわかりました。
加えて、同調査の別の切り口によるデータベースから「平均在院日数」「年齢階層別」「二次医療圏」「病院開設者別」「県外受診者数」などさまざまな切り口からの分析も可能と思われます。
今回の分析はここまでとして、上記の切り口を加えた分析を今後の検討課題とします。
今回作成したファイルがご入用の方は下記ココナラコンテンツにご用意しております。
このようなデータ集計、分析等にご興味がございましたら、下記サービスをご検討頂けますと幸いです。