●ビッグデータを使ってPythonで株価データ分析します。
プログラム言語が多く存在する中、なぜ、Pythonなのか?
それは、Pythonはライブラリが豊富で、ライブラリを使用することにより複雑な処理をシンプルなコードで(簡単に)実現出来てしまうからです。
例えば、Pythonでどのようなことができるか? プログラムを書いてみました。
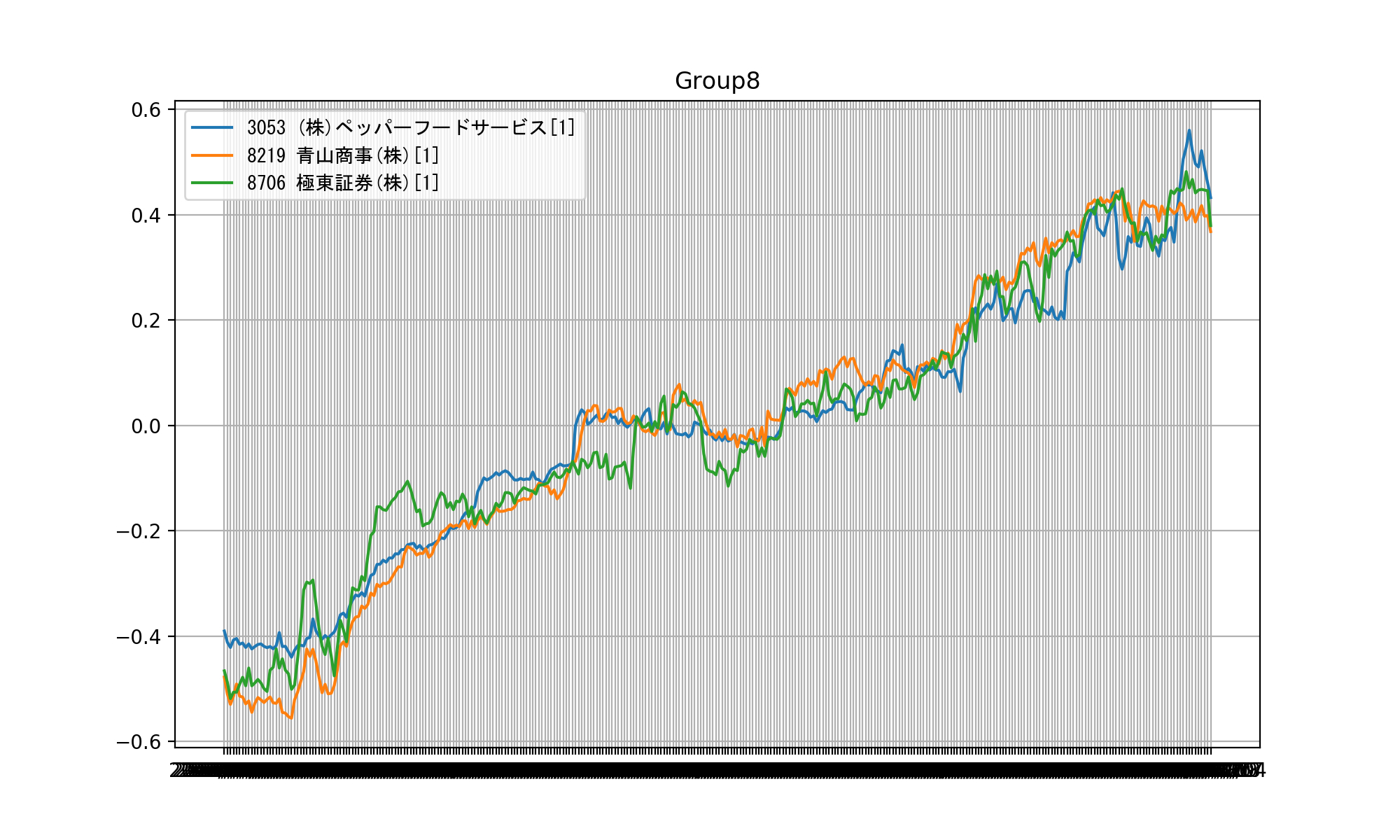
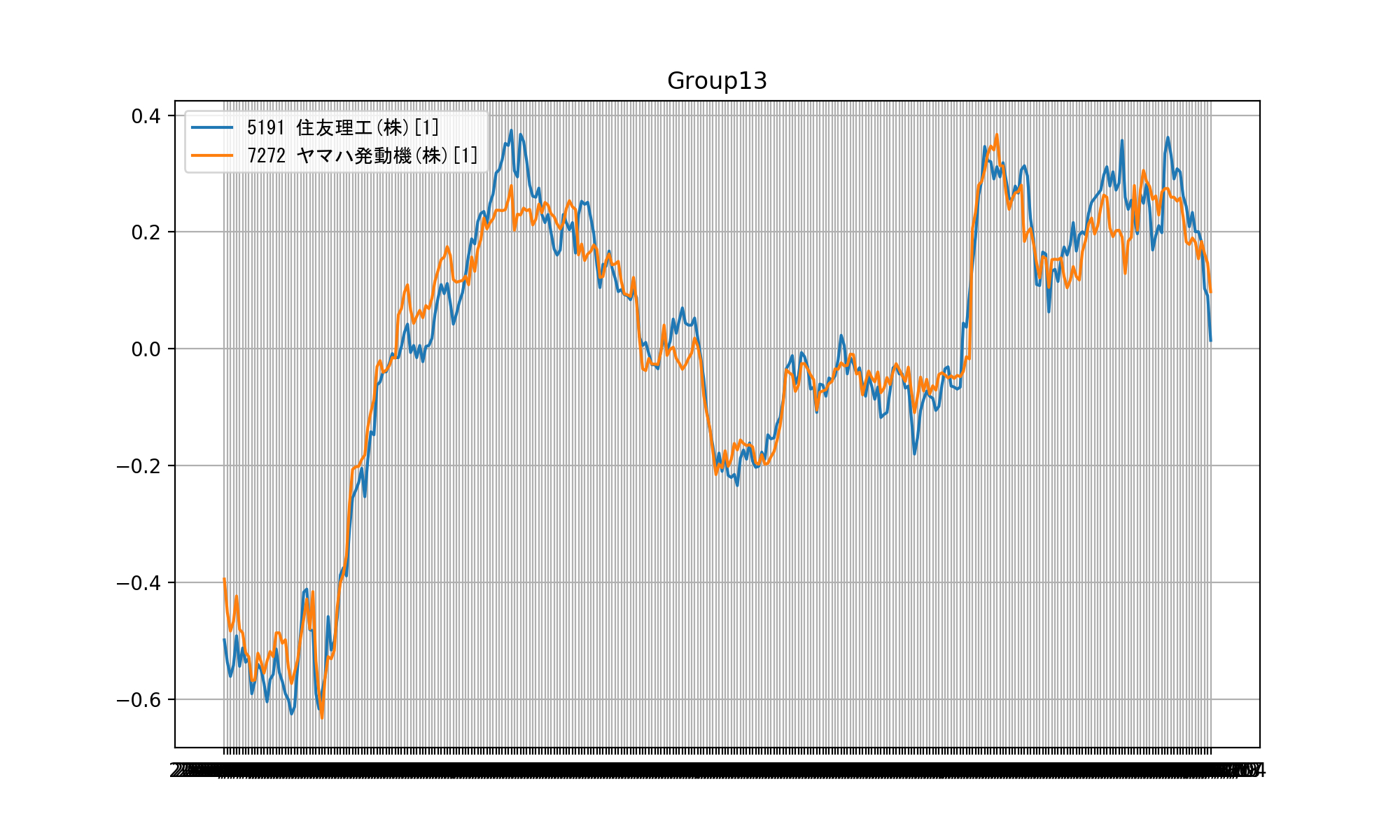
今回作成したプログラムは、日足データを用いてチャートパターンが類似しているものをグループ化し、それをビジュアル化するものです。
■ 類似チャートをビジュアライズした画像
日足データを使用しており、グラフの縦軸は価格でノーマライズしています。
■ ソースコード
ソースコードは公開しますが、動作は保証はいたしかねます。
(1) 類似しているチャートをグルーピングするプログラム
import glob
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from concurrent.futures import ThreadPoolExecutor
group_list = []
csv_path = "D:\データ\Python\csv"
save_path = "D:\データ\Python\img"
#################################
# 相関係数を算出する
#################################
def calc_correlation(df1, df2):
#終値のDataFrameをSeriesに格納
s1 = df1['Close']
s2 = df2['Close']
#データ正規化
s3 = (s1 - s1.min()) / (s1.max() - s1.min())
s4 = (s2 - s2.min()) / (s2.max() - s2.min())
#相関係数を算出
coefficient = round(s3.corr(s4), 5)
return coefficient
#################################
# グルーピング処理
#################################
def set_group(code1, code2, coefficient):
found = False
prev_num = 0
wklist = []
#既存のグループにコードが存在するかチェック
for wklist in group_list:
if code1 in wklist:
wklist.append(code2)
found = True
break
elif code2 in wklist:
wklist.append(code1)
found = True
break
#新規グループ作成
if found == False :
wklist = []
wklist.append(code1)
wklist.append(code2)
group_list.append(wklist)
num = len(group_list)
if num > prev_num :
print(len(group_list))
prev_num = num
#################################
# グループリスト出力
#################################
def out_group_list():
f = open('group.txt', 'w')
no = 0
for group in group_list:
no += 1
line = "(" + str(no) + ") [ "
for lp in range(0, len(group)):
line += str(group[lp])
if ( lp < len(group) - 1 ):
line += ","
line += " ]\n\n"
f.write(line)
f.close()
#################################
# メイン
#################################
f = open('result.txt', 'w')
# ファルダ内のファイル一覧を取得
files = glob.glob(csv_path + "\*")
df = {}
for i in range(0, len(files)):
code = files[i].replace( csv_path + "\\", "").replace( ".csv", "")
print(code)
df[code] = pd.read_csv(files[i])
for i in range(0, len(files)):
for j in range(i+1, len(files)):
#ファイルパスの不要な部分を削除し、コードのみ取り出す
code1 = files[i].replace( csv_path + "\\", "").replace( ".csv", "")
code2 = files[j].replace( csv_path + "\\", "").replace( ".csv", "")
#CSVを読込み
df1 = df[code1]
df2 = df[code2]
#相関係数を算出する
coefficient = calc_correlation(df1, df2)
#相関係数が高いものをファイルに出力する
if ( coefficient >= 0.98 ):
#ファイル出力
strline = code1 + " - " + code2 + " : " + str(coefficient)
print(strline)
f.write(strline + "\n")
f.flush()
#グルーピング処理
set_group(code1, code2, coefficient)
# ファイルクローズ
f.close()
#グループリスト出力
out_group_list()
(2) 類似チャートを描画してビジュアライズするプログラム
import pandas as pd
from matplotlib import pyplot as plt
import sys
csv_path = "D:\データ\Python\CSV"
save_path = "D:\データ\Python\img"
stock_name_list = {}
# コマンドライン引数
param = []
#################################
# データの正規化
#################################
def normalise_df(df):
s1 = df['Close']
s2 = df['Date']
normalise_s1 = (s1 - s1.mean()) / (s1.max() - s1.min())
# データをノーマライズ
norm_close_list = normalise_s1.values.tolist()
# 日付のリスト
date_list = s2.values.tolist()
# 列と行を入れ替え
norm_data_list = []
for i in range(0, len(date_list)):
norm_data_list.append( [ norm_close_list[i], date_list[i] ] )
return norm_data_list
#################################
# グラフ描画
#################################
def draw_graph(group_no, group):
# figureを作成
fig = plt.figure(figsize=(10,6), dpi=200)
# figureにaxes(座標軸)を追加 - 引数(行数,列数,プロット番号)
ax = fig.add_subplot(1,1,1)
for i in range(0, len(group)):
# コード
code = group[i]
# ファイルパスの不要な部分を削除し、コードのみ取り出す
file_path = csv_path + "\\" + str(code) + ".csv"
# CSVを読込み DataFrameに格納
df = pd.read_csv(file_path)
# データの正規化
if ( len(param) > 1 and param[1] == '1' ):
norm_data_list = normalise_df(df)
colum = ['Close', 'Date']
df2 = pd.DataFrame(data=norm_data_list, columns=colum)
else:
df2 = df
# グラフ描画
graph_label = code + " " + stock_name_list[code]
ax.plot('Date', 'Close', data=df2, label=graph_label)
# グループ名セット
group_name = "Group" + str(group_no)
# タイトルセット
ax.set_title(group_name)
# 凡例を表示
ax.legend(loc=0, prop={"family":"MS Gothic"})
# グリッド表示
ax.grid(True)
# 画像保存
plt.savefig(save_path + "\\" + group_name + ".png")
#################################
# ファイルから銘柄名を取得
#################################
def get_stock_name():
with open('企業概要リスト.txt', encoding="utf-8") as f:
for line in f:
vals = line.split(',')
market = vals[2][0:3]
stock_name_list.update({vals[0] : vals[1] + market})
f.close()
#################################
# メイン
#################################
param = sys.argv
# ファイルから銘柄名を取得
get_stock_name()
no = 0
with open("group.txt") as f:
# 1行読込み
for line in f:
if ( line != '' ) :
pos1 = line.find('[')
if ( pos1 >= 0 ) :
pos2 = line.find(']')
val = (line[pos1+2:pos2-1])
# カンマ区切りで配列にする
group = val.split(',')
no += 1
# グラフ描画
if ( len(group) < 20 ):
draw_graph(no, group)
f.close()
株価データとプログラミング知識があれば、様々な株価の分析が可能です。