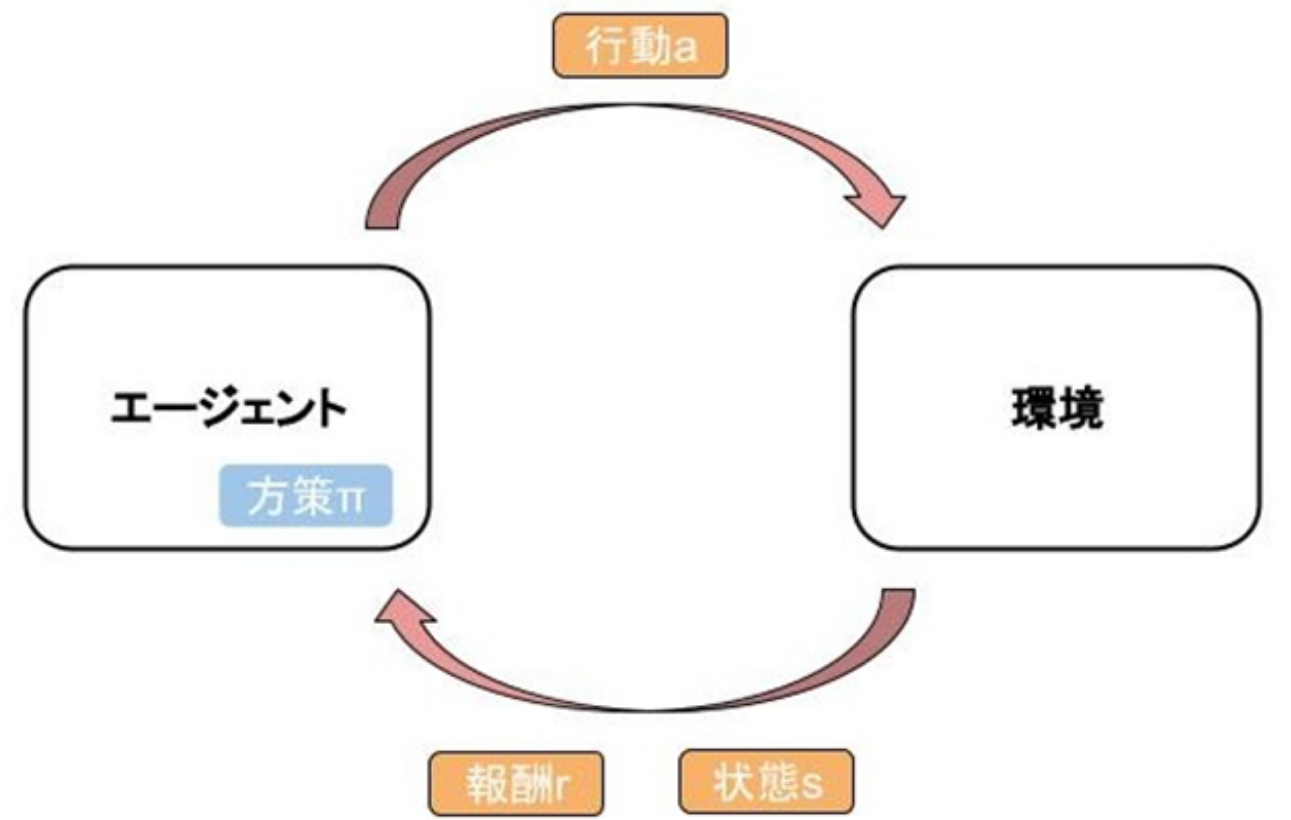
強化学習(Reinforcement Learning)とは、ある条件下にある環境の中で、目的として設定された報酬を最大化するように、モデルが学習を行う学習手法です。
学習を行うモデル(エージェント)は、方策πを持ちます。方策とは、状態を与えたとき、行動を返す関数です。行動の結果として返ってくる状態sと、それを加味して算出する報酬rを用いてエージェントは適切な行動を学習していきます。
以上が強化学習の大まかな流れですが、強化学習の学習方法には、大きく分けて二つあります。価値学習(Value Learning)と方策学習(Policy Learning)です。
価値学習(Value Learning)
価値学習を端的に説明すると、長期的に見て報酬を多くもらえる行動を近似した表を作る学習方法です。行動と状態を与えたとき、最適な解を返す関数を作るイメージです。一般にこのような関数はQ関数と呼ばれ、その学習方法はQ学習と呼ばれます。価値学習は決定論的な学習方法であるため、学習できるのは離散的な行動に限ります。
方策学習(Policy Learning)
方策学習は、方策そのものを学習によって求める学習方法です。方策は確率分布となるため、報酬が多くもらえる形に確率分布を更新することで、エージェントの行動を最適化します。方策学習は確率論的な学習方法であるため、連続的な行動を学習することができます。
方策学習を用いた車モデルの強化学習
方策学習を用いて、車モデルをPythonによる物理シミュレーション環境PyBulletを用いて強化学習を行うコードを販売しています。
また、PyBulletの基本的な導入と操作については、以下のブログで紹介しています。
Pythonのコード開発・バグ修正
Pythonコードの開発・バグ修正を承っています。