netkeibaからデータを取得するの第三弾です。
前回は取得済みのレース一覧または指定の日付範囲から出走表と結果を取得しました。
今回は馬ごとのプロフィールと過去成績を取得していきます。
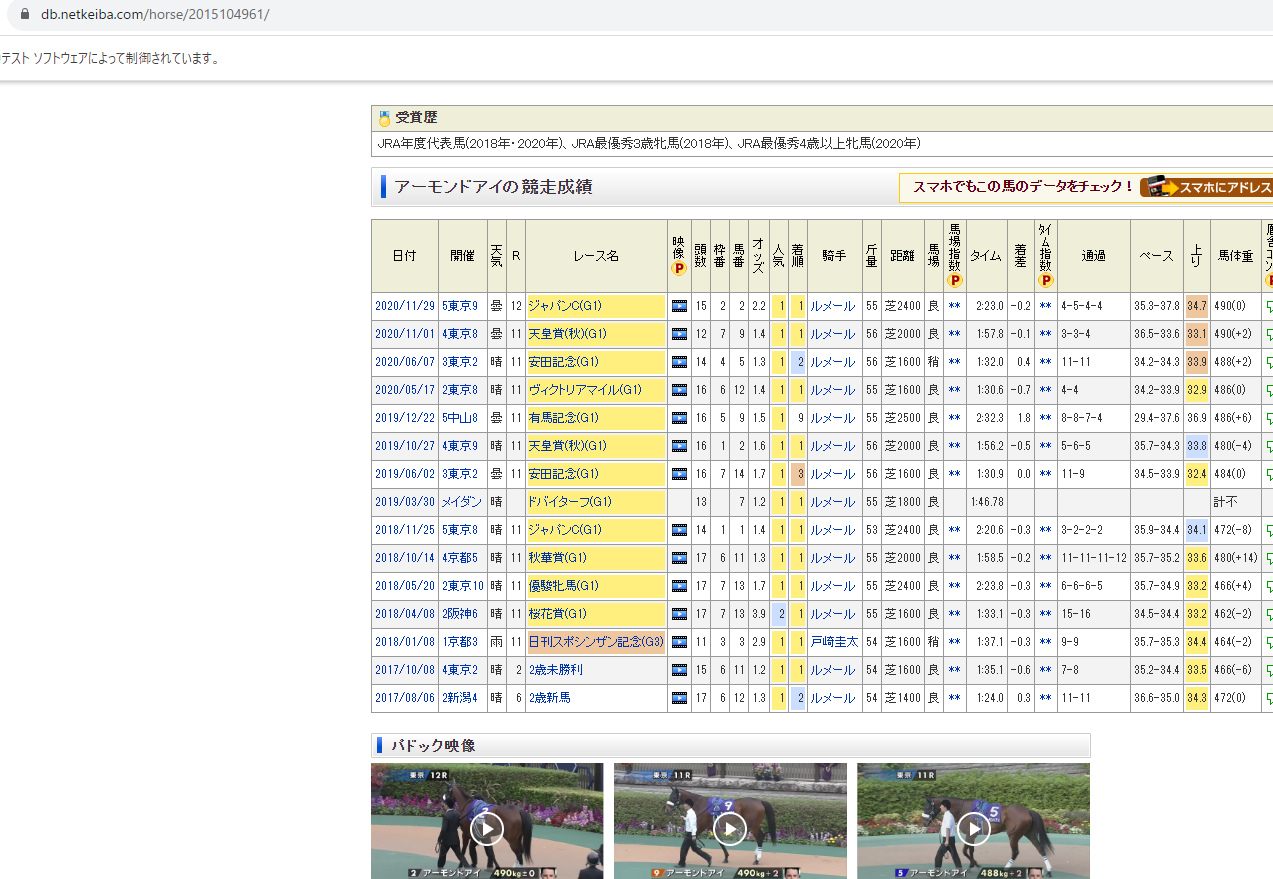
競走馬のページを確認
特定の馬のページは以下
urlに’horse/{horse_code}/’という形でページ分けされています。
今回欲しい情報はページ上部中央のプロフィールとその下にある過去レースの成績一覧です。
取得テスト
前回のブログをご覧になった方なら、テーブル状になってるからpandasで簡単に取得できるかも!ということがわかるかもしれません。
試しにやってみましょう。
前回同様にdriverをgetするところからです
from time import sleep
import pandas as pd
driver = get_driver()
# アーモンドアイのページを取得
driver.get(r"/horse/2015104961") # 使用不可文字なのでドメイン部分を追記してください
sleep(3) # 遅延
data = pd.read_html(driver.page_source)
取得したdataを確認します
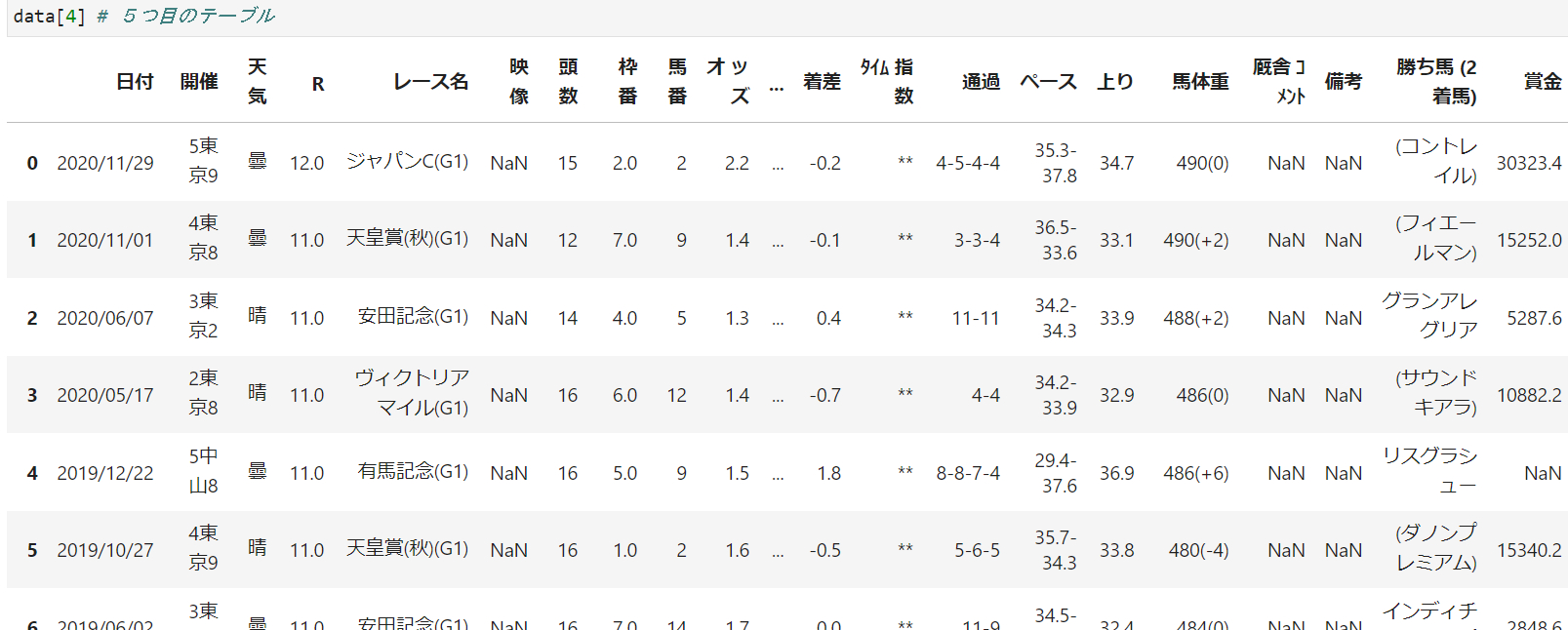
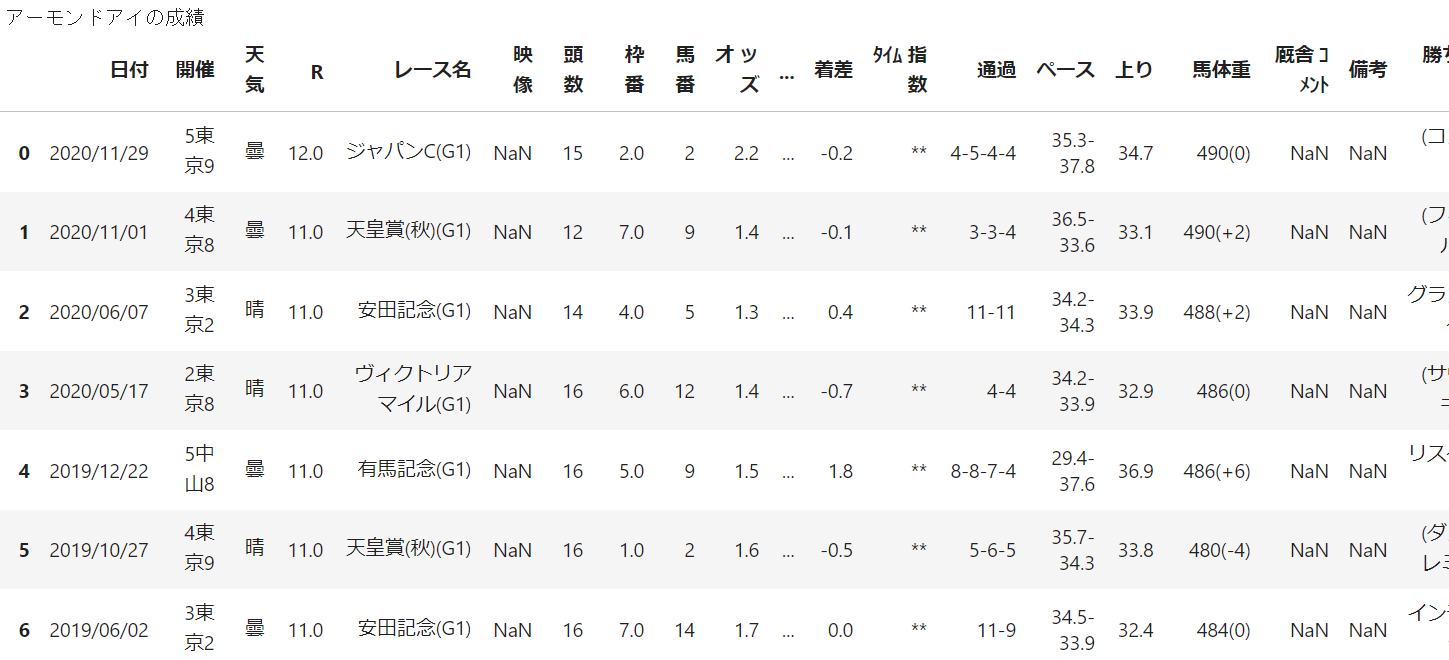
これをみると2つ目と5つ目を取得すれば問題なさそうですが、実はそう上手く行かず。。
というのも4つ目のテーブルを見てみると
この受賞歴の欄は、優秀な実績を残した馬にのみ与えられる賞で、ほとんどの馬には存在しない欄なのです。
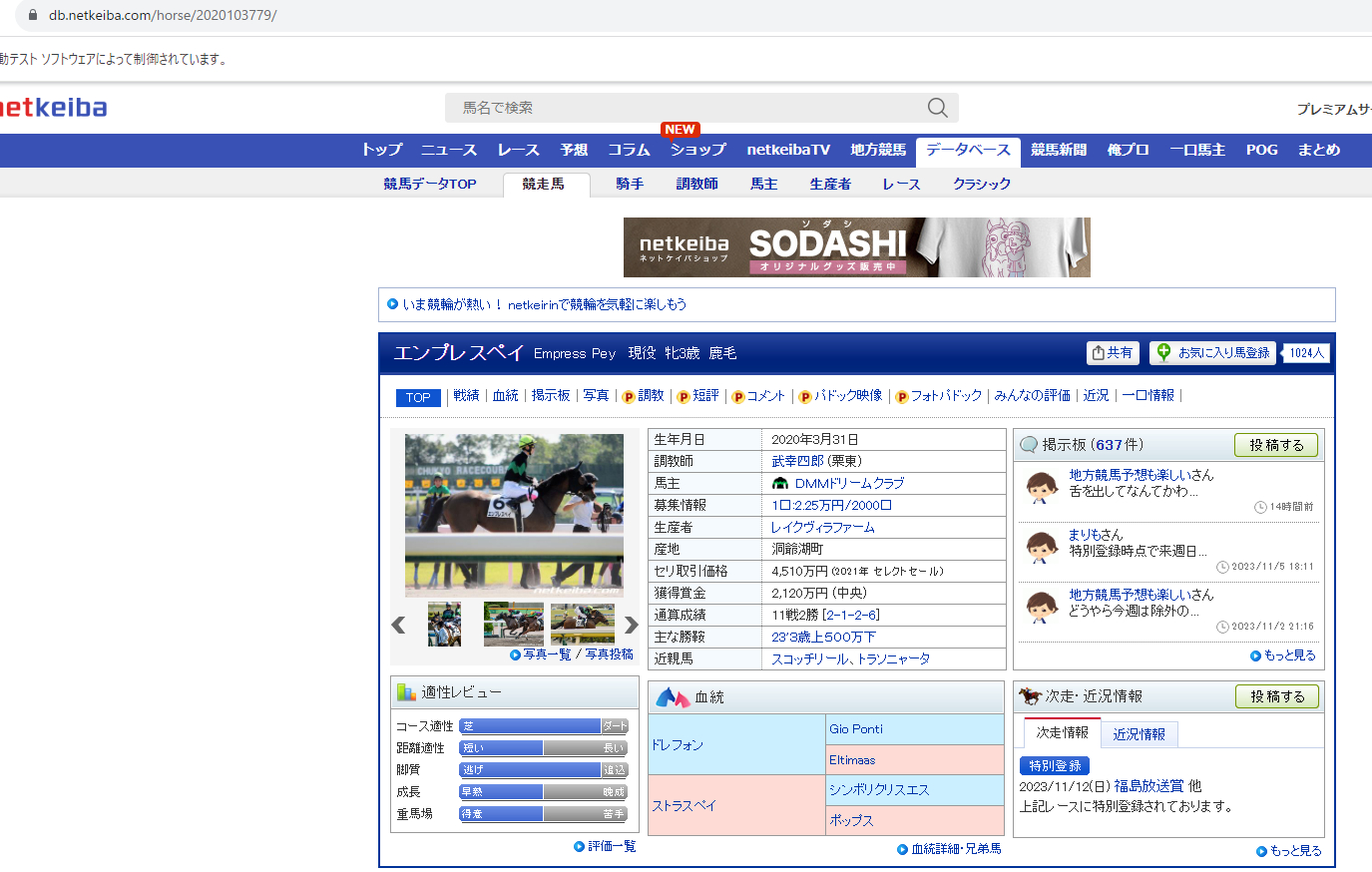
試しに重賞馬ではない他の馬を見てみましょう。
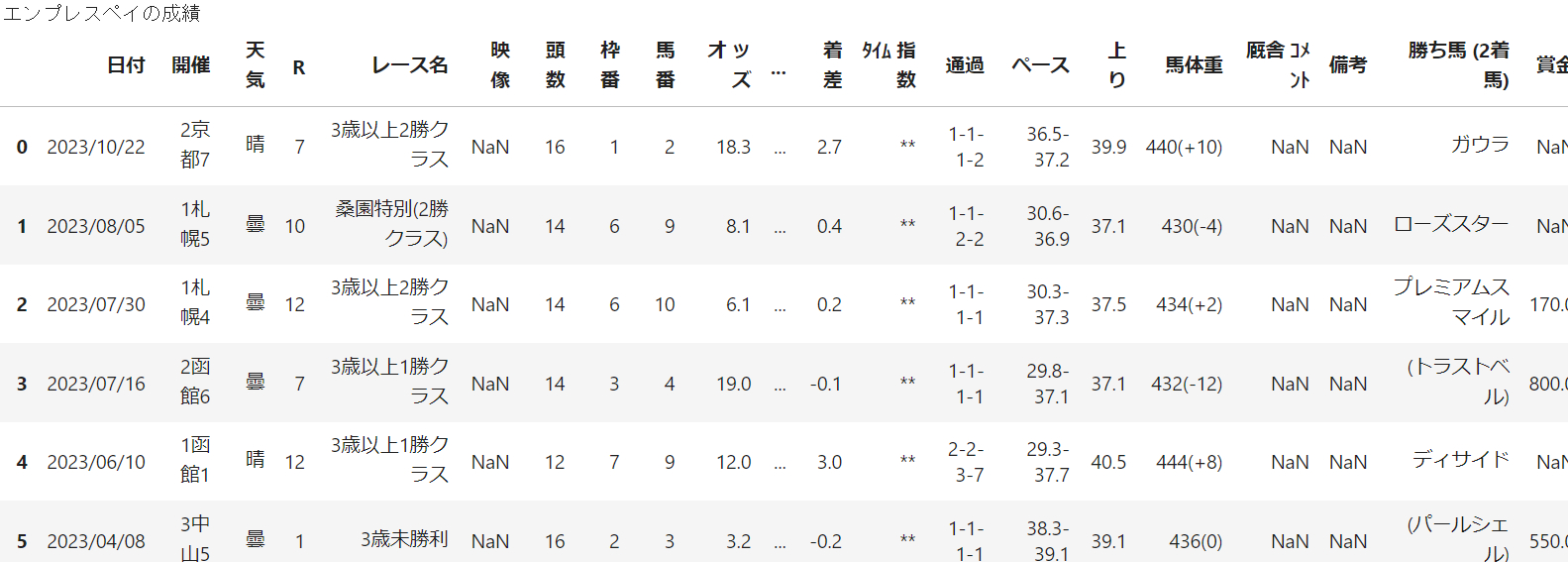
この馬は現在2勝クラスで活躍中のエンプレスペイという馬です。
余談ですが、私がDMMの一口馬主で出資している馬なので注目してみてください。おそらく次の土日に出走します。
この馬で先程のアーモンドアイと同様にデータを取得して見てみましょう。
# エンプレスペイのページを取得
driver.get(r"/horse/2020103779") # 使用不可文字なのでドメイン部分を追記してください
sleep(3) # 遅延
data = pd.read_html(driver.page_source)
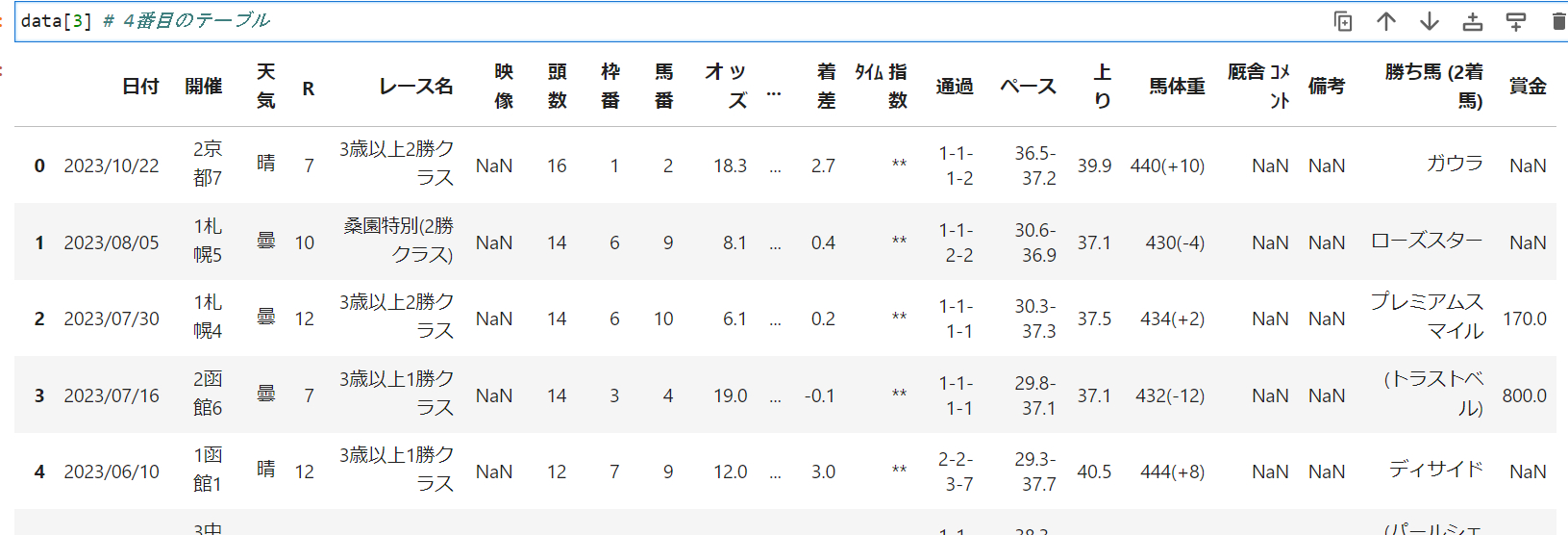
結果
先程は5つめ(data[4])で取得できました。今回はdata[3]です
前述の通り、受賞歴がない馬は4番目に前倒しで格納されています
なので、馬情報取得の関数をpandasを使って取得する場合は以下のように場合分けをする必要があります。
取得コード
def get_horse_data(driver, umacd):
url = f"/horse/{umacd}" # 禁止文字なので追記してください
driver.get(url)
sleep(3)
data = pd.read_html(driver.page_source)
profile_df = data[1]
results_df = data[3]
if "着 順" not in results_df.columns:
# 4つ目のテーブルに【着順】という列が無ければ受賞歴とみなし、5番目のテーブルを代入する
results_df = data[4]
return profile_df, results_df
この関数で再度、アーモンドアイとエンプレスペイのプロフィールと過去成績を取得してみましょう
AlmondEye = ("アーモンドアイ","2015104961")
profile_df, results_df = get_horse_data(driver, AlmondEye[1])
print(f"{AlmondEye[0]}のプロフィール")
display(profile_df)
print(f"{AlmondEye[0]}の成績")
display(results_df)
EmpressPey = ("エンプレスペイ","2020103779")
profile_df, results_df = get_horse_data(driver, EmpressPey[1])
print(f"{EmpressPey[0]}のプロフィール")
display(profile_df)
print(f"{EmpressPey[0]}の成績")
display(results_df)
このように場合分けして取得できました。あとは前回取得した出走表からumacdをループすれば全データ取得可能です。
今回のスクレイピングの課題点・問題点・注意点
まず今回のように馬の情報を取得しようとすると、
例えば1日に開催場所が3箇所×レース数12×出走馬数平均12とすると432回馬のページをリクエストして取得することになります。
もしページをリクエストして3秒待機する処理を行っていた場合、1296秒つまり22分かかります。多くの日数のデータを取得する場合はかなりの時間がかかることになります。
また、netkeibaのページはグーグルアドをロードするため、表示に非常に時間がかかります。
これはページを完全に読み込む前にHTMLを解析してしまい、エラーの原因となることが1点と
有料会員でログインすれば広告がロードされないため表示を時間短縮出来ますが、Amazonなどのサイト同様、アカウントでログインすることはすなわち利用規約に同意したものとみなされるため
スクレイピング禁止というように解釈されることが一般的ですので、自己責任でお願いします。
また、技術者であれば、マルチスレッドや複数のプロセスから実行することもあり得ると思いますが、待機時間を設けることが意味するように同時に多くのリクエストを送信することはサーバへの妨害とみなされてアクセスブロックされるリスクがあることも考慮が必要です。
通信が得意な技術者ならルーティングやプロキシを設定することもあるでしょうが、これも同様です。
サーバに負荷をかけることなくデータ収集と分析を楽しみましょう。
最後に
今回作成したツールではプロフィール、過去レースの成績一覧に加えて、血統(父や母など5代血統)や各リンク先のコード(調教師やレースID等や母や父のコード)を取得できます。
次回は未定ですが、一連のデータ取得とデータベースに格納するツールを作成するか、分析をテーマに記事を書こうと思います。