サービス
サービスを探す
プロ人材を探す
仕事を探す
ブログを探す
サービス
サービスを探す
プロ人材を探す
仕事を探す
ブログを探す
購入・発注したい方
サービスを探す
プロ人材を探す
ノウハウ・素材を探す
ブログを探す
仕事・求人を投稿して募集
エージェントに人材を紹介してもらう
受注・働きたい方
出品する
単発の仕事を探す
継続 (時給/月給) の仕事を探す
エージェントに仕事を紹介してもらう
カテゴリ一覧
イラスト作成・漫画制作
デザイン制作
Web制作・HP作成・EC構築
動画編集・映像制作
集客・マーケティング相談
NEW
ビジネス代行・事務代行
音楽制作・ナレーション
IT相談・システム開発
ライティング・翻訳
コンサルティング・士業
生成AI活用・開発・制作
NEW
占い
悩み相談・カウンセリング
学習指導・資格・キャリア相談
住まい・美容・生活相談
オンラインレッスン・習い事
ハンドメイド制作
出張撮影・出張サービス
資産運用・副業の相談
NEW
弁護士検索・法律Q&A(法律相談)
サポート
はじめての方へ
ご利用ガイド
お困りのときは
ログイン
会員登録
サービスを探す
イラスト作成・漫画制作
デザイン制作
Web制作・HP作成・EC構築
動画編集・映像制作
集客・マーケティング相談
NEW
ビジネス代行・事務代行
音楽制作・ナレーション
IT相談・システム開発
ライティング・翻訳
コンサルティング・士業
生成AI活用・開発・制作
NEW
占い
悩み相談・カウンセリング
学習指導・資格・キャリア相談
住まい・美容・生活相談
オンラインレッスン・習い事
ハンドメイド制作
出張撮影・出張サービス
資産運用・副業の相談
NEW
プロ人材を探す
ノウハウ・素材を探す
ブログを探す
求人募集を投稿する
人材を紹介してもらう
仕事を探す
出品する
仕事を探す
仕事を紹介してもらう
出品する
仕事を紹介してもらう
求人募集を投稿する
人材を紹介してもらう
ブログを投稿
会員登録で10%割引クーポンを獲得!
会員登録で10%割引クーポンを獲得!
ココナラブログ
ホーム
ブログトップ
ブログ
学び
【サイバーエージェント】独自の日本語LLM(大規模言語モデル)を開発
記事
学び
株式会社タカマサ【集客のプロ集団】
2023/05/16 17:42
こんにちは!株式会社タカマサの青山です。
最近、AIの進化を感じることが増えましたね!
例えば、「ChatGPT」
英語などの翻訳から、プログラミングまで自動でやってくれるという優れものですね。
その中で、日本屈指のインターネット広告代理店「サイバーエージェント」が
独自の日本語LLM(Large Language Model、大規模言語モデル)を開発したことを発表しました。
これは一体どういうことなのでしょうか?
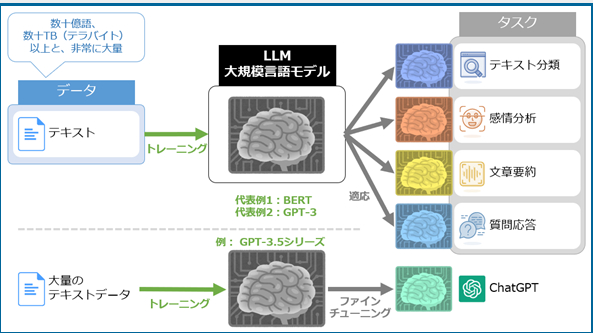
LLM(大規模言語モデル:Large Language Model)とは?
LLM
は、大量のテキストデータを使ってトレーニングされた自然言語処理のモデルのことです。
一般的には大規模言語モデルをファインチューニングなどすることによって、
テキスト分類や感情分析、情報抽出、文章要約、テキスト生成、質問応答といった、さまざまな自然言語処理(NLP:Natural Language Processing)タスクに適応できます。
大規模言語モデルの代表例としては、
2018年にGoogleが発表した「BERT」や、
2020年にOpenAIが発表した「GPT-3」などが挙げられる。
2022年12月に発表された「ChatGPT」は、2022年初頭にトレーニングした「GPT-3.5シリーズ」をチャット(対話)向けにファインチューニングしたものであり、大規模言語モデルの応用例の一つです。
独自の日本語LLM(大規模言語モデル)について
本モデルはすでに130億パラメータまでの開発が完了しており、サイバーエージェントが提供する「極予測AI」「極予測TD」「極予測LP」などAIを活用した広告クリエイティブ制作領域のサービスにおいて活用を始めています。
また、日本語に特化した独自の大規模モデルを開発したので、サイバーエージェントが保有する大規模な日本語データを活かした独自モデルを開発したことで、従来よりも自然な日本語の文章生成が可能となります。
これによってどうなる?
🔴クリエイティブをAIが全て制作する時代が来るということ。
チャットGPTのように
「全てやってくれる」
ことが広告制作でも可能になるということです。
オンライン広告においては、さまざまな生成パターンに対してその効果を計測できる環境があります。
ここ数ヶ月で発達してきたAI技術には、学習済みのモデルの出力をこのようなインプットを元に素早くチューニングできるLoRAなどの技術があります。これまでAIモデルの再学習には大規模な計算が必要でしたが、動的に、連続的にモデルのトレーニングが行えるようになってきました。
このような前提を踏まえると、広告にはとても面白い可能性が秘められています。ただ、宣伝と詐欺は紙一重なところもあり、技術が人を騙すことや、さらには世論の操作などに使われる可能性もリアルに感じられます。
終わりに
いかがだったでしょうか?
AIの進化は素晴らしい反面、人の手を離れていくことで代理店の在り方、強みのないクリエイターはどんどん淘汰されていく時代になるでしょう。
人にしかできない、クリエイティブや広告制作は存在するはずです。
これからの時代、AIの進化に負けないくらい人も進化しないといけませんね。
#AI
#テクノロジー
一覧に戻る