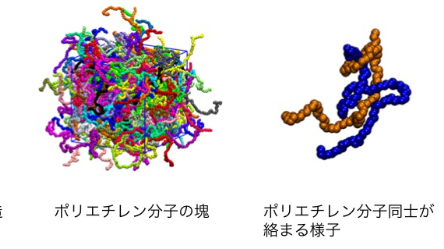
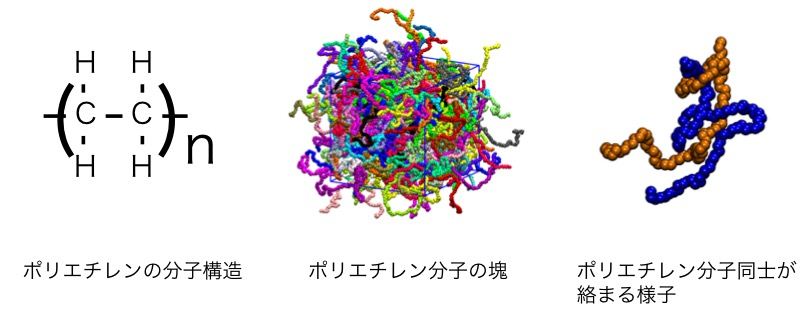
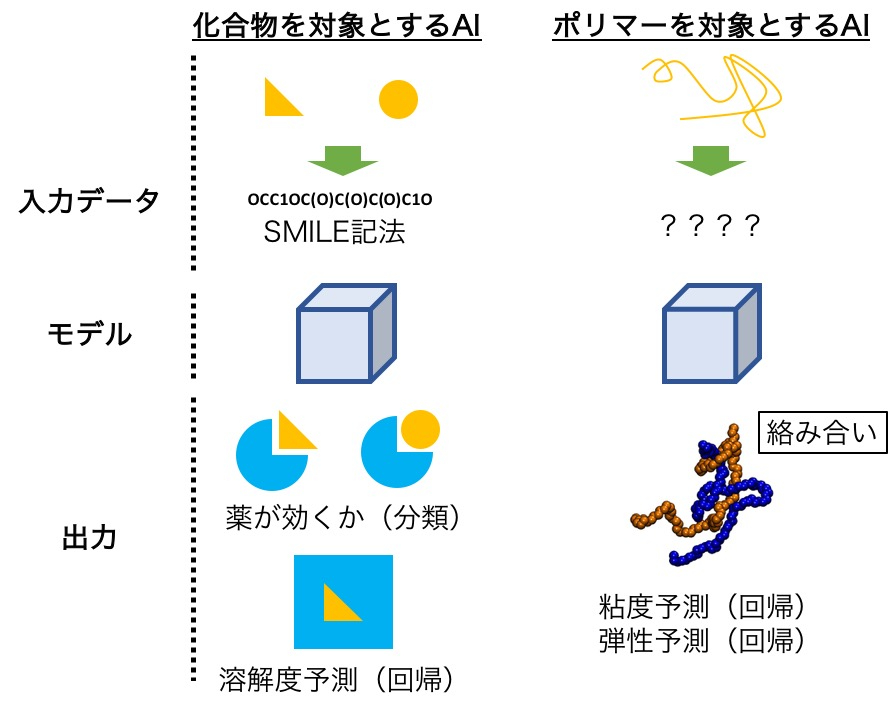
このような分子的背景を持つポリマーは、なぜAIを用いたマテリアルデザインが難しいのでしょうか。アメリカ国立標準技術研究所(NIST)のA. J. Debraらが出した論文を参考にしながら、要因をまとめます [A. J. Debra et al., ACS Macro Lett. 6, 1078 (2017)]。
ポリマーのデータ不足
A. J. Debraらは、まず、ポリマーのデータ不足を指摘しました。タンパク質や化合物は、古くからデータベースが確立されており、RCSBが管理するタンパク質構造データバンク(PDB)はその中でも代表的なデータベースです。一方、ポリマーにおいては、データベースが確立されていないため、ビッグデータの利を適用できていないようです。Debraらは、特に以下をポリマーデータベース作成時の困難点として挙げています: